“기밀은 잊어드릴게요”… 망각하는 AI 뜬다
- 동아일보
-
입력 2026년 4월 28일 00시 30분
공유하기
글자크기 설정
데이터 마구잡이로 학습하던 AI… 비밀-저작권 자료까지 출력해 논란
ICLR서 AI 기억 분석 ‘허블’ 공개… AI 암기력 낮추는 방법도 가능해져
챗GPT에 저작권 소송 낸 NYT… 기사 도용 여부 기술적 입증 쉬워져

“기억을 지워 드립니다.”
영화 ‘이터널 선샤인’의 두 주인공은 서로의 기억을 지우기 위해 특정 기억만 삭제해 주는 회사 ‘라쿠나’를 찾는다. 이처럼 오랜 시간 영화 속 상상에 머물러 있던 ‘선택적 망각’이 인공지능(AI) 업계에서는 현실 과제로 떠올랐다. 방대한 데이터를 닥치는 대로 학습하며 성장해 온 AI가 회사 기밀 정보까지 그대로 ‘기억’해 출력하는 사례가 잇따르고 있기 때문이다. ‘기업용 AI’에 매진하고 있는 빅테크들 사이에서 민감한 정보만 AI에서 선택적으로 제거하는 ‘언러닝(unlearning)’ 기술이 주목받고 있는 가운데 ‘선택적 망각’ 현실화의 기반이 될 도구도 등장했다.
● 기밀 정보 ‘선택적 망각’하는 AI 나오나

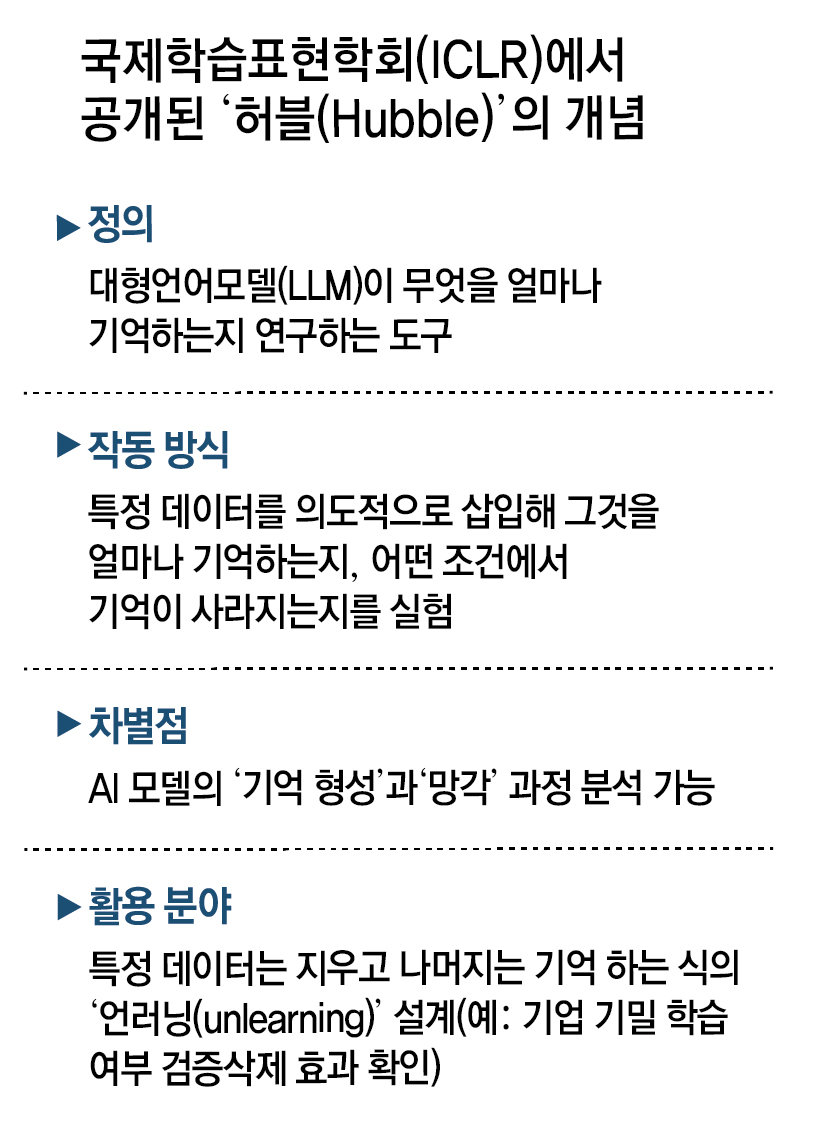
로빈 지아 미국 서던캘리포니아대(USC) 교수와 독일 막스플랑크 연구진 등이 공동 개발한 ‘허블(Hubble)’은 AI가 특정 데이터를 언제, 어떤 방식으로 학습할 때 더 강하게 기억하는지, 또 반대로 기억이 사라지는지 분석하는 도구다. 쉽게 말해 허블을 이용하면 AI의 암기력을 높이거나 혹은 낮추는 방법을 알 수 있는 것이다.
연구자들이 주목한 것은 암기력을 ‘낮추는’ 쪽이다. 주요 기업들이 업무에 AI를 도입할 때 가장 민감하게 보는 요소가 바로 회사의 기밀 정보 유출 가능성이다. AI가 내부 문서나 고객 데이터를 그대로 기억해 이를 외부에 노출시키는 경우 치명적인 리스크로 이어질 수 있기 때문이다. 국제학술지 사이언스는 “대규모언어모델(LLM)이 민감한 정보를 그대로 복사하는 ‘암기’ 문제는 AI 개발자들에게 큰 골칫거리”였다고 언급했다.
허블을 활용하면 AI가 회사의 기밀 정보를 기억하고 있는지를 확인할 수 있고, 더 나아가 특정 데이터는 암기하지 않도록 설계하거나 선택적으로 기억을 제거하는 ‘언러닝’ 기술 개발로 이어질 수 있다는 평가다. 특히 AI 인프라 구축에 수천만 달러를 쏟아부으며 매출 압박에 시달리고 있는 빅테크들 입장에서 기밀 유출 리스크를 제거한 ‘기업용 AI’는 ‘황금알 낳는 거위’가 될 수 있다. 허블에 대한 관심이 커질 수밖에 없는 이유다. 우사이먼성일 성균관대 소프트웨어학과·인공지능대학원 교수는 “특정 데이터가 실제로 모델 학습에 영향을 미쳤는지를 확인할 수 있을 뿐 아니라 ‘언러닝’ 이후 해당 정보가 실제로 제거됐는지를 입증하는 수단으로도 활용될 수 있다”고 말했다.
● “기억, 무엇을 남겨야 하냐가 핵심”
저작권 소송에도 허블의 영향력이 커질 수 있다는 관측이다. 뉴욕타임스는 오픈AI의 챗GPT가 자사 기사를 그대로 베끼고 복제했다며 저작권 침해 소송을 제기했다. 기존에는 이를 파악하려면 수천만 건의 사용자 대화 기록 등을 분석해야 했지만, 허블과 같은 도구를 활용하면 AI가 데이터를 어떻게 기억하고 활용하고 있는지 기술적으로 빠르게 입증할 수 있다.
업계에서는 그간 ‘미지의 영역’로 여겨졌던 AI 내부의 기억 저장 과정을 들여다볼 수 있는 도구가 등장했다는 점에서 의미가 크다는 평가도 나온다. AI를 보다 통제 가능한 시스템으로 전환할 수 있는 가능성이 열렸다는 것이다.
4차 산업혁명 시대 >
구독

© dongA.com All rights reserved. 무단 전재, 재배포 및 AI학습 이용 금지
트렌드뉴스
-
1
한국 축구팬 향해 ‘눈찢은’ 멕시코 협회장…결국 직위 해제
-
2
조국보다 사랑 택한 캐나다 前 총리…연인과 美개막전 관람
-
3
감자튀김과 당뇨의 뜻밖의 관계…20만명 40년 추적해 보니
-
4
한동훈에 패한 하정우 “수첩 들고 다시 구포시장으로”
-
5
브라질 몰아붙인 모로코 돌풍…‘카타르 4강’은 이변이 아니었다
-
6
‘시간당 30㎜’ 소나기에 우박까지…서울 올해 첫 호우주의보
-
7
발명가 공대생 된 성동일 아들…“아빠가 대학축제 와서 춤춰”
-
8
SKY 등 10개大, 28학년도 수시에 ‘N수생’ 지원 자격 대폭 제한
-
9
“대안 없어” vs “사퇴해야”…의원총회 장동혁 거취 분수령
-
10
鄭 “정권은 짧다”에…靑 내부 “대통령 탄핵 협박 아니냐” 분노
-
1
“대안 없어” vs “사퇴해야”…의원총회 장동혁 거취 분수령
-
2
李 “與, 방해 뚫고 국민 먹고사는 문제 해결해야…구호 말고 실행 집중하라”
-
3
안민석 “‘참교육’ 교권보호국, 경기교육청에도”…공개 토론 제안
-
4
한동훈에 패한 하정우 “수첩 들고 다시 구포시장으로”
-
5
나경원 “오세훈, 재선거해도 압승…6·3 부정선거, 책임은 李대통령”
-
6
트럼프 “이란과 14일 합의 서명”…혁명수비대 “트럼프 생일날은 아냐”
-
7
鄭 “정권은 짧다”에…靑 내부 “대통령 탄핵 협박 아니냐” 분노
-
8
노태악, 선거前 3개월간 34일만 출근… 근무한 날 절반은 4시간 이하 머물러
-
9
[사설]“尹 계엄 하려 北 도발 유도”… 무지한 건지, 무모한 건지
-
10
李 “6·15 남북공동선언, 역사 전환점…희망의 불씨 살아있다 믿어”
트렌드뉴스
-
1
한국 축구팬 향해 ‘눈찢은’ 멕시코 협회장…결국 직위 해제
-
2
조국보다 사랑 택한 캐나다 前 총리…연인과 美개막전 관람
-
3
감자튀김과 당뇨의 뜻밖의 관계…20만명 40년 추적해 보니
-
4
한동훈에 패한 하정우 “수첩 들고 다시 구포시장으로”
-
5
브라질 몰아붙인 모로코 돌풍…‘카타르 4강’은 이변이 아니었다
-
6
‘시간당 30㎜’ 소나기에 우박까지…서울 올해 첫 호우주의보
-
7
발명가 공대생 된 성동일 아들…“아빠가 대학축제 와서 춤춰”
-
8
SKY 등 10개大, 28학년도 수시에 ‘N수생’ 지원 자격 대폭 제한
-
9
“대안 없어” vs “사퇴해야”…의원총회 장동혁 거취 분수령
-
10
鄭 “정권은 짧다”에…靑 내부 “대통령 탄핵 협박 아니냐” 분노
-
1
“대안 없어” vs “사퇴해야”…의원총회 장동혁 거취 분수령
-
2
李 “與, 방해 뚫고 국민 먹고사는 문제 해결해야…구호 말고 실행 집중하라”
-
3
안민석 “‘참교육’ 교권보호국, 경기교육청에도”…공개 토론 제안
-
4
한동훈에 패한 하정우 “수첩 들고 다시 구포시장으로”
-
5
나경원 “오세훈, 재선거해도 압승…6·3 부정선거, 책임은 李대통령”
-
6
트럼프 “이란과 14일 합의 서명”…혁명수비대 “트럼프 생일날은 아냐”
-
7
鄭 “정권은 짧다”에…靑 내부 “대통령 탄핵 협박 아니냐” 분노
-
8
노태악, 선거前 3개월간 34일만 출근… 근무한 날 절반은 4시간 이하 머물러
-
9
[사설]“尹 계엄 하려 北 도발 유도”… 무지한 건지, 무모한 건지
-
10
李 “6·15 남북공동선언, 역사 전환점…희망의 불씨 살아있다 믿어”
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개
![사찰에서 올린 전통혼례… MZ세대 ‘나만의 결혼식’ [청계천 옆 사진관]](https://dimg.donga.com/a/464/260/95/1/wps/NEWS/FEED/Donga_Home_News2/134107022.1.thumb.jpg)




댓글 0