공유하기
[기고] 서비스형 머신러닝(MLaaS) 시대의 기회와 도전과제
- 동아닷컴
-
입력 2021년 2월 10일 19시 53분
글자크기 설정
머신러닝(ML)은 이제 경쟁우위를 확보하려는 기업에게 반드시 필요한 기술이다. 막대한 양의 데이터를 빠른 속도로 처리할 수 있기 때문에, 기업/브랜드가 고객에게 좀더 적합한 상품을 추천하거나, 제조 기업이 공정 과정을 개선한다거나, 또는 시장 변화를 예측해 선제 대응할 수 있도록 지원할 수 있다.
머신러닝 기술을 서비스 형태로 이용할 수 있는 \'서비스형 머신러닝(MLaaS, Machine Learning as a Service)\'은, 사업적 맥락에서 고객에게 일관된 서비스를 지속 제공하는 머신러닝 모델을 설계, 구현하는 기업들로 정의될 수 있다. 특히, 고객 수요와 행동이 급변하는 영역에서 큰 역할을 수행할 수 있는데, 지난 해부터 이어지고 있는 코로나19 대유행이 대표적인 사례다.

코로나19의 영향으로 쇼핑, 업무, 사회 활동 방식이 크게 바뀌었으며, 그에 대응하기 위해 기업들은 빠르게 서비스 방식을 바꿔야 했다. 이는 곧, 데이터를 수집, 처리하는 데 이용하는 기술 또한 새로운 데이터 입력에 맞춰 유연하게 조정할 수 있어야 함을 의미한다. 그래야만 기업이 최선의 의사결정을 신속하게 내릴 수 있다.
그런데, 머신러닝 모델을 MLaaS로 전환하는 데 해결해야 할 난관이 하나 있다. 머신러닝 모델을 구축하고, 머신러닝 관련 인재들에게 이를 전달, 교육하는 방식과 관련된 문제다.
현재 대다수의 머신러닝 모델 연구/개발 작업은 특징과 레이블이 사전 부여된 일련의 훈련용 데이터(training data)를 활용하는 개별 모델을 구축해, 테스트용 데이터(test data)라는 다른 데이터 세트의 레이블을 가장 잘 예측하도록 만드는 데에 초점을 맞춘다. 그러나 늘 변화하는 고객 수요에 부응하려는 기업들의 실제 사례를 보면, 훈련용 데이터와 테스트용 데이터의 경계가 점점 모호해지고 있다. 테스트 또는 예측을 위해 현재 다루고 있는 데이터를 훈련용 데이터로 활용함으로써 향후 좀더 나은 모델을 기대할 수 있는 것이다.
결과적으로, 모델 훈련에 사용되는 데이터는 여러 이유로 불완전할 수밖에 없다. 현실의 데이터 소스가 불완전하거나 개방형 고객 설문조사처럼 비구조형 데이터가 될 수 있고, 편향된 수집 절차에서 발생했을 수도 있다. 예를 들어, 추천 모델 훈련에 사용될 데이터는 일반적으로, 현재 구동 중인 다른 온라인 추천 시스템의 피드백으로 얻은 결과에 토대를 두고 있어, 이 데이터는 해당 추천 서비스 모델에 의해 편향될 수 있다.
일반적으로 구매와 같이 퍼널(funnel), 즉 깔때기의 아래쪽에서 일어나는 활동은 깔때기 위쪽의 활동보다 유도하기가 훨씬 어렵다. 만약 MLaaS 모델이 클릭과 확인 수 같은 단순 지표에만 의존한다면, 마케팅 메시지 발송 시기 등의 추천 활동 또한 비즈니스 최종 목적과 일치하지 않게 된다.
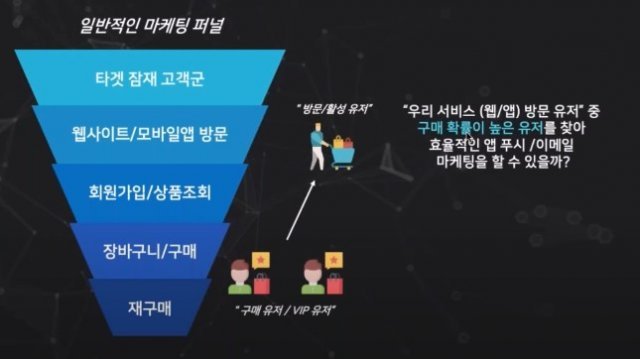
끝으로, 머신러닝 서비스를 제공하는 B2B 인공지능 기업이라면 보통 수천 명, 또는 그 이상의 고객에게 여러 도메인에서 서비스를 제공해야 한다. 즉 최소한 수천 개의 모델이 온라인에서 지속적으로 구동되고 있다는 소리다. 끊임없이 변화하는 사업 방향에 이런 모델이 제대로 부응하려면, 매일 재훈련되거나 갱신되는 현실의 시나리오를 따라잡을 수 있어야 한다. 이를 달성하려면 자동 훈련 파이프라인을 설계해야 하는 것은 물론이고, 모델이 잘못된 로컬 최적 지점으로 수렴될 가능성을 0에 가깝게 낮춰야 한다.
MLaaS 모델의 전반적인 안정성과 일관성을 보장하는 것이 무엇보다 중요하다. 분명 이는 어려운 일이고 많은 비용 투자와 연구, 실험 등이 요구되지만, 이를 통해 기업이 얻을 보상은 실로 막대하다. 변화하는 비즈니스 환경에 맞춰 선제 대응하며 시장 경쟁에서 앞서갈 원동력을 얻을 수 있기 때문이다. MLaaS 모델의 작동 원리, 효과, 도입 전후 문제점 등 모든 사항을 현실적으로 따져보고 각 기업에 적합한 형태로 활용할 수 있다면, 급변하는 세계 시장에서 결정적 경쟁력을 확보하게 될 것이다.

애피어 머신러닝 최고과학자 슈드 린(Shou-de Lin)
국립대만대학교 컴퓨터과학/정보공학 교수로 재직 중 2020년 애피어에 합류했다. 로스 알라모스 내셔널 랩에서 박사 학위 취득 후 연구원으로 근무한 바 있으며, 현재 애피어의 최고 머신러닝 과학자로서 인공지능 연구팀을 이끌며 첨단 머신러닝 기술의 연구 및 응용에 주력하고 있다.
정리 / 동아닷컴 IT전문 이문규 기자 (munch@donga.com)
기고 >
구독
![독감 자가검사 키트는 일상 건강관리 문화 출발점[기고/유미화]](https://dimg.donga.com/a/180/101/95/2/wps/NEWS/IMAGE/2026/07/02/134221143.1.jpg)
이런 구독물도 추천합니다!
-

고양이 눈
구독
-

송평인 칼럼
구독
-

이은화의 미술시간
구독
트렌드뉴스
-
1
[단독]與, 홍명보·정몽규 불러 청문회 연다…‘감독 선임’ 추궁
-
2
유튜버 육은영쌤, 日서 ‘어깨빵 남성’ 참교육 눈길
-
3
수려한 외모에 집안일·대화 가능…中 ‘반려 로봇’ 주문 1만 3000대 돌파
-
4
[단독]개표 오류 3곳 추가 확인…경기도·시흥시·김천시
-
5
“이게 뭐야?” 보도 위 ‘삐죽’ 나온 볼트에 쾅!…540억 청구
-
6
“거실에 누웠는데 뱀이”…양주 아파트 배수관 타고 들어온 듯
-
7
“배재고 앞 근조화환 발로 뻥…재학생 반성 안해” 주장글 확산
-
8
‘손흥민에 임신 협박’ 여성 징역 4년·남성 공범 2년 확정
-
9
李, 박정희·DJ 언급하며 “3대 메가 프로젝트는 역사적 결단”
-
10
배우 최상엽, 이봉원·박미선 아들이었다…“성 바꿔 데뷔”
-
1
李 “압력 넣는다고 옮기는 기업 어딨나…그런 생각이 구태”
-
2
“스벅 가야지” 배재고, 6개월 출전정지…“선수는 조사뒤 심의”
-
3
“배재고 앞 근조화환 발로 뻥…재학생 반성 안해” 주장글 확산
-
4
한동훈 “배재고 잘못했지만, 스벅도 영업정지 안 당해…징계 과도”
-
5
李, 박정희·DJ 언급하며 “3대 메가 프로젝트는 역사적 결단”
-
6
[단독]“호남 최대 태양광 발전, 0~6시 전력공급 0.01%”
-
7
광주 반도체 단지에 주52시간 완화 검토
-
8
한국사 강사 최태성, 배재고 논란에 “저 자신 부끄러워”
-
9
‘광주 팹’ 주52시간 완화 검토…세제-금융-인허가 원스톱 지원
-
10
선관위, 이제서야 “투표지 100% 인쇄”… 노태악 “배우자 출장비 반납”
트렌드뉴스
-
1
[단독]與, 홍명보·정몽규 불러 청문회 연다…‘감독 선임’ 추궁
-
2
유튜버 육은영쌤, 日서 ‘어깨빵 남성’ 참교육 눈길
-
3
수려한 외모에 집안일·대화 가능…中 ‘반려 로봇’ 주문 1만 3000대 돌파
-
4
[단독]개표 오류 3곳 추가 확인…경기도·시흥시·김천시
-
5
“이게 뭐야?” 보도 위 ‘삐죽’ 나온 볼트에 쾅!…540억 청구
-
6
“거실에 누웠는데 뱀이”…양주 아파트 배수관 타고 들어온 듯
-
7
“배재고 앞 근조화환 발로 뻥…재학생 반성 안해” 주장글 확산
-
8
‘손흥민에 임신 협박’ 여성 징역 4년·남성 공범 2년 확정
-
9
李, 박정희·DJ 언급하며 “3대 메가 프로젝트는 역사적 결단”
-
10
배우 최상엽, 이봉원·박미선 아들이었다…“성 바꿔 데뷔”
-
1
李 “압력 넣는다고 옮기는 기업 어딨나…그런 생각이 구태”
-
2
“스벅 가야지” 배재고, 6개월 출전정지…“선수는 조사뒤 심의”
-
3
“배재고 앞 근조화환 발로 뻥…재학생 반성 안해” 주장글 확산
-
4
한동훈 “배재고 잘못했지만, 스벅도 영업정지 안 당해…징계 과도”
-
5
李, 박정희·DJ 언급하며 “3대 메가 프로젝트는 역사적 결단”
-
6
[단독]“호남 최대 태양광 발전, 0~6시 전력공급 0.01%”
-
7
광주 반도체 단지에 주52시간 완화 검토
-
8
한국사 강사 최태성, 배재고 논란에 “저 자신 부끄러워”
-
9
‘광주 팹’ 주52시간 완화 검토…세제-금융-인허가 원스톱 지원
-
10
선관위, 이제서야 “투표지 100% 인쇄”… 노태악 “배우자 출장비 반납”
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개



댓글 0