[단독]네이버, ‘국가대표 AI’ 개발에 中기술 차용… 경쟁사 “AI 주권 확보 불가능” 문제 제기
- 동아일보
공유하기
글자크기 설정
네이버 “검증된 인코더 사용은 상식”
경쟁사 “단순 부품 아닌 핵심 모듈”
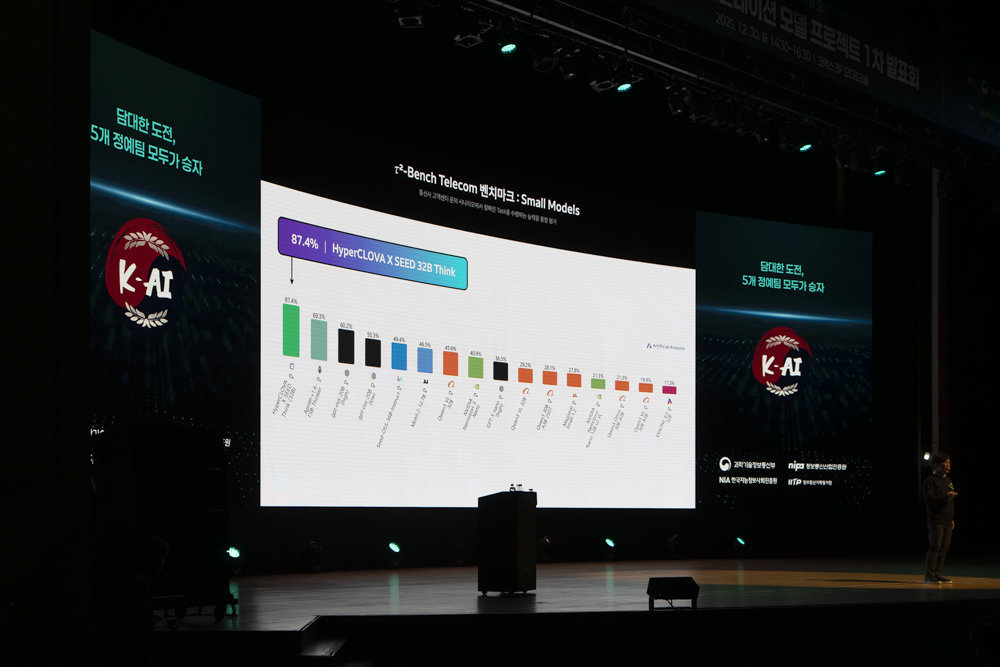
‘국가대표 AI’를 개발하겠다는 정부의 ‘독자 AI 파운데이션’ 사업이 논란에 휩싸였다. 네이버가 중국 알리바바의 인공지능(AI) 모델 ‘큐웬(Qwen)’의 이미지와 음성 인코더를 차용했다고 인정한 가운데, 경쟁 기업에서 평가 기관 측에 공식 문제 제기를 한 것으로 확인됐다.
7일 정보기술(IT) 업계에 따르면 독자 AI 파운데이션 선발전에 참여한 5개 정예팀 중 1곳이 평가 기관으로 참여 중인 한국정보통신기술협회(TTA)에 기술 검토 보고서를 제출했다. 네이버가 공개한 ‘하이퍼클로바X-띵크-32B·옴니-8B’ 모델에 활용된 이미지·음성 인코더가 알리바바 ‘큐웬 2.5 ViT’의 것을 차용한 데 따른 것이다.
동아일보가 입수한 이 보고서는 “(최신 연구들에 따르면) 인코더는 단순 부품이 아닌 핵심 지능 모듈”이라며 “비전(시각) 인코더의 품질은 멀티모달 대형언어모델(MLLM) 최종 성능의 상한선을 결정한다”고 지적했다. 또 “외부 인코더에 의존하는 모델은 지각적 특징 추출 단계부터 타사 아키텍처에 종속된다”며 “진정한 의미의 AI 주권 확보를 불가능하게 한다”고 강조했다.
하지만 업계에서는 “향후 라이선스 문제가 발생할 수 있다”고 우려한다. 정부도 지난해 7월 사업 공고 당시 독자 AI 파운데이션의 조건을 두고 “해외 모델 미세조정(파인튜닝) 등으로 개발한 파생형 모델이 아닌, 모델의 설계부터 사전 학습 과정 등을 수행한 국산 모델(타사 모델에 대한 라이선싱 이슈 부재)”이라고 명시하기도 했다.
단독 >
![[단독]대한상의 포럼에 국회의장 첫 참석…조정식, 내달 재계와 만남](https://dimg.donga.com/a/180/101/95/2/wps/NEWS/IMAGE/2026/06/16/134121126.1.jpg)
이런 구독물도 추천합니다!
-

정도언의 마음의 지도
구독
-

함께 미래 라운지
구독
-

고양이 눈
구독
© dongA.com All rights reserved. 무단 전재, 재배포 및 AI학습 이용 금지
트렌드뉴스
-
1
권은빈, 26세에 연예계 떠난다…“껍데기 인간관계, 공허-불안 시달려”
-
2
백종원·소유진 막내딸, 걸그룹 뺨치는 춤 실력 자랑
-
3
“이란에 항복, 빌어먹을 MOU”…美보수, 트럼프에 불만 폭발
-
4
盧사위 곽상언 저격 사흘만에…유시민, 노무현 재단 떠나
-
5
B-52 폭격기, 美기지서 이륙 직후 추락…탑승자 전원 사망
-
6
CLC 권은빈, 연예계 은퇴 “공허함·불안함 시달렸다”
-
7
‘0’ 하나 잘못 붙여…18억 아파트 172억에 낙찰
-
8
‘이승기·이무진 미정산’ 차가원 대표, 300억대 사기 혐의 영장 신청
-
9
“임산부석 앉은 중년 여성, 자기도 임신했다며 양보 거부”
-
10
장동혁 “전국 재선거가 목표”…오세훈 “자리보전용 구호 멈춰라”
-
1
오세훈 “장동혁 재선거 주장 소모적…자리보전용 구호 멈춰라”
-
2
장동혁 “전국 재선거가 목표”…오세훈 “자리보전용 구호 멈춰라”
-
3
사퇴론 몰린 장동혁 “전국 재선거 소청”… 당내 “무책임한 행동”
-
4
시위자 1명이 문앞 저지…체육단체, 野중재에도 진입 못했다
-
5
한병도 “국힘이 맡았던 경제관련 상임위원장 회수 검토”
-
6
“투표용지 보관할 곳 없다” 선관위 직원들 요청에 인쇄 줄여
-
7
잠실 시위대·경찰 대치…“체육회 업무 차질” 강제진입 가능성
-
8
국힘 재선거 요구 기준 ‘고무줄’…대구·경남 빠지고, 서울은 포함
-
9
“임산부석 앉은 중년 여성, 자기도 임신했다며 양보 거부”
-
10
이준석 “탈모가 생존 문제냐…건보는 정치 하사품 아냐”
트렌드뉴스
-
1
권은빈, 26세에 연예계 떠난다…“껍데기 인간관계, 공허-불안 시달려”
-
2
백종원·소유진 막내딸, 걸그룹 뺨치는 춤 실력 자랑
-
3
“이란에 항복, 빌어먹을 MOU”…美보수, 트럼프에 불만 폭발
-
4
盧사위 곽상언 저격 사흘만에…유시민, 노무현 재단 떠나
-
5
B-52 폭격기, 美기지서 이륙 직후 추락…탑승자 전원 사망
-
6
CLC 권은빈, 연예계 은퇴 “공허함·불안함 시달렸다”
-
7
‘0’ 하나 잘못 붙여…18억 아파트 172억에 낙찰
-
8
‘이승기·이무진 미정산’ 차가원 대표, 300억대 사기 혐의 영장 신청
-
9
“임산부석 앉은 중년 여성, 자기도 임신했다며 양보 거부”
-
10
장동혁 “전국 재선거가 목표”…오세훈 “자리보전용 구호 멈춰라”
-
1
오세훈 “장동혁 재선거 주장 소모적…자리보전용 구호 멈춰라”
-
2
장동혁 “전국 재선거가 목표”…오세훈 “자리보전용 구호 멈춰라”
-
3
사퇴론 몰린 장동혁 “전국 재선거 소청”… 당내 “무책임한 행동”
-
4
시위자 1명이 문앞 저지…체육단체, 野중재에도 진입 못했다
-
5
한병도 “국힘이 맡았던 경제관련 상임위원장 회수 검토”
-
6
“투표용지 보관할 곳 없다” 선관위 직원들 요청에 인쇄 줄여
-
7
잠실 시위대·경찰 대치…“체육회 업무 차질” 강제진입 가능성
-
8
국힘 재선거 요구 기준 ‘고무줄’…대구·경남 빠지고, 서울은 포함
-
9
“임산부석 앉은 중년 여성, 자기도 임신했다며 양보 거부”
-
10
이준석 “탈모가 생존 문제냐…건보는 정치 하사품 아냐”
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개

![[사설]“한계기업 퇴출시켜야 경제에 이득”… 정부가 서둘러야 할 일](https://dimg.donga.com/a/464/260/95/1/wps/NEWS/FEED/Donga_Home_News2/134124787.1.thumb.jpg)

댓글 0