공유하기
인포플라 “대답만 하던 기존 AI의 한계, VLM 기반 자동화로 극복”
- 동아닷컴
-
입력 2024년 5월 18일 15시 08분
글자크기 설정
올해 AWS 서밋은 60여개의 파트너사가 부스를 꾸리고 2만 9000여명의 인원이 참가해 국내 클라우드 관련 행사 중 최대 규모를 뽐냈다. 특히 올해 행사는 최근 시장의 최대 화두로 떠오른 생성형 AI 관련 혁신을 이끄는 기술과 제품, 그리고 서비스가 다수 소개되어 큰 관심을 끌었다.

이날 발표를 진행한 최인묵 인포플라 대표는 반복적인 업무를 자동화하는 RPA(Robotic Process Automation) 솔루션에 대한 가능성, 그리고 한계를 명확히 하는 것으로 운을 띄웠다. 특히 기존의 스크립트 기반 RPA를 비전공자가 원활하게 이용하기 위해서는 전문가의 도움이 필요한 점을 언급했다. 또한, 웹이나 앱 내에서 이루어지는 반복 작업을 RPA로 자동화한 경우, 갑작스럽게 팝업 창의 등장이나 화면 장애 등의 돌발변수에 제대로 대응하지 못해 RPA가 정지하는 등의 문제가 있다고 지적했다.
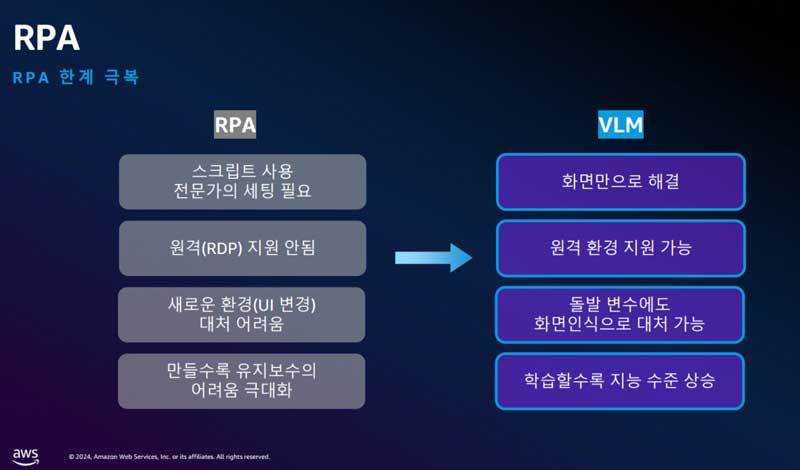
인포플라는 이러한 기존 RPA의 한계를 극복하는 방안으로 ‘VLM(Vision Language Model)’을 제안했다. 이는 거대 언어 모델, LLM(Large language model)에 이미지 처리능력을 더한 것이다. 스크립트가 아닌 화면 인식만으로 모든 문제를 해결할 수 있으며, 원격 환경도 지원이 가능한 점 등, 기존 RPA의 한계를 다수 극복할 수 있다.
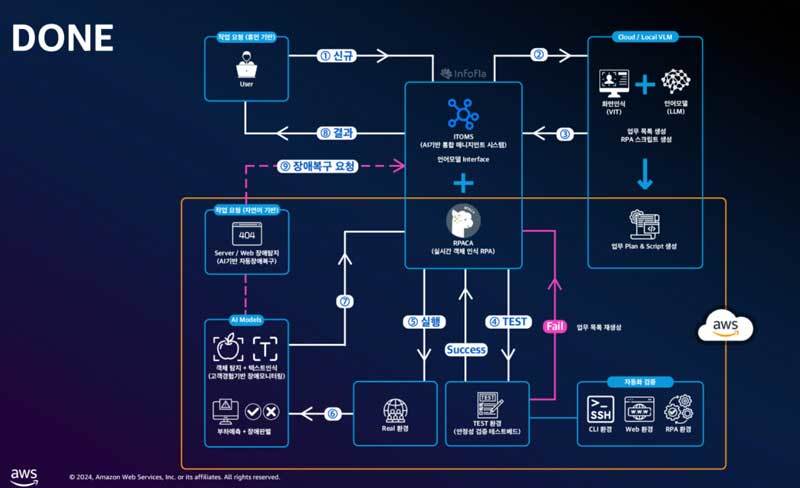
이와 관련, 이날 인포플라는 자사에서 개발한 ‘VLAgent(VLM + Agent)’를 제안했다. 이는 VLM을 통해 화면을 인지하고 명령을 수행할 수 있는 에이전트 모델을 의미한다. 스크립트의 수동 제작이 불필요하며, AI가 화면을 이해하고 작업 플랜 및 액션 플랜의 생성 및 실행을 자동으로 수행할 수 있는 것이 특징이다.
이는 LLM과 AI 에이전트, 그리고 업무 자동화 등의 최근의 트렌드를 한데 모은 것이다. 또한, 단순히 사용자의 질문에 답변만 하는 기존 AI 서비스와 달리, 실행을 통한 문제 해결까지 이어진다는 것도 차별점이다. 또한 기존의 모델은 고해상도 영상을 인식하고 대응하는 과정에서 지나치게 높은 처리 능력을 요구하기도 했고, 한글을 지원하지 않아 국내 사용자들이 이용하기에 불편을 주기도 했다.
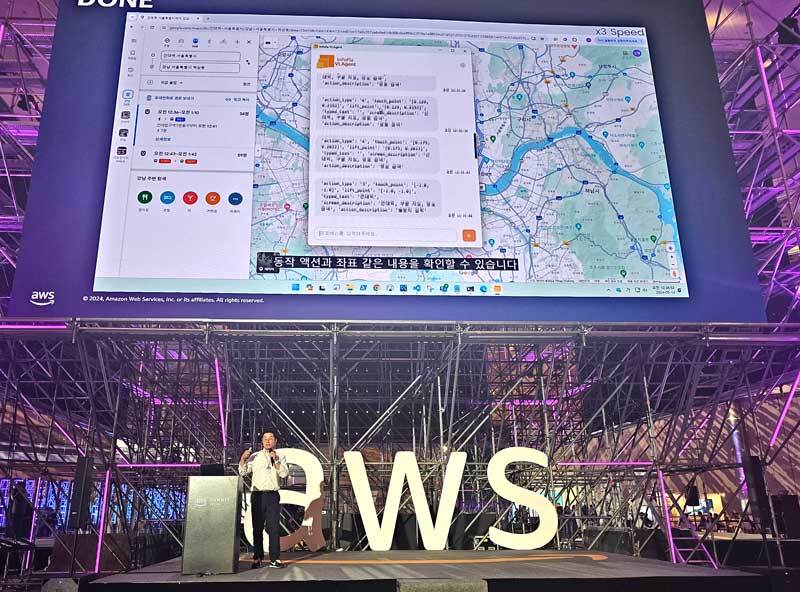
이날 발표 중 인포플라는 시연 영상을 보여주기도 했다. 윈도 운영체제 기반의 PC에서 VLAgent에 “건대역에서 강남역까지 경로를 알려줘”라는 내용의 명령을 입력하자, AI가 마우스와 키보드를 제어해 바탕화면의 ‘크롬’ 웹 브라우저를 실행하고 ‘구글 지도’ 서비스를 선택한 후, 출발지(건대역)와 도착지(강남역)을 입력해 경로를 검색하는 과정까지 자동 완료했다.
한편, 최인묵 인포플라 대표는 이날 발표를 마무리하며 “우리의 솔루션은 서비스 및 업무 자동화, 시각 장애인 지원, 엔터테인먼트 사업, 교육 및 제조, 의료, 고객서비스 등 다양한 분야에서 활용이 가능하다”며, “사실상 국내에선 최초의 시도이며, 해외에서도 유사한 사례를 찾기 힘들다”고 강조하기도 했다.
iT동아 김영우 기자 pengo@itdonga.com
트렌드뉴스
-
1
‘월급 50만원, 아파트는 4억’ 베트남…청년들 “그냥 평생 월세 살란다”[딥다이브]
-
2
한동훈 “2030년 정권 되찾겠다…2028년 총선 ‘보수 다수당’ 목표”
-
3
내년 환갑이지만…“근육운동 덕분에 은퇴 뒤 설계까지 끝내”[양종구의 100세 시대 건강법]
-
4
‘멸공라떼’ 내놓은 대전 카페, 태극기 잘못 그려…건곤감리 틀려 역풍
-
5
‘집회가요, 지도부, 인쇄물’ 없는 이런 시위는 처음 본다[청계천 옆 사진관]
-
6
“이화영 유죄, 李정권 ‘무고의 굿판’ 끝…민주당 사과해야” 野 맹공
-
7
“내 신청곡 왜 취소해” 소주병으로 머리 내려친 70대 산악회원
-
8
李 조작기소 특검 발단 “연어 술파티”…법원 판단은 “거짓말”
-
9
“1000만원 줄 테니 나가달라”…집주인 제안, 받아도 될까 [집과법]
-
10
반도체→부동산 ‘富의 이동’ 원천차단?…‘보유-양도세’ 꺼낸 김용범
-
1
[단독]노태악, 선관위서 수당 4년간 1.8억 받아…3배 ‘셀프 증액’도
-
2
위기때면 단식-입원, ‘소나기’ 피하는 장동혁
-
3
李 조작기소 특검 발단 “연어 술파티”…법원 판단은 “거짓말”
-
4
李 “선관위 원포인트 개헌, 필요땐 대통령 발의”
-
5
한동훈 “2030년 정권 되찾겠다…2028년 총선 ‘보수 다수당’ 목표”
-
6
“투표지 축소 인쇄 보고 못받았다”던 노태악, 뒤늦게 말바꿔
-
7
李 “우리 돈으로 우리 방위 책임질건데, 전작권 왜 美가 갖나”
-
8
李 “우리 돈으로 방위 책임, 전작권 왜 美가 갖나”
-
9
‘멸공라떼’ 내놓은 대전 카페, 태극기 잘못 그려…건곤감리 틀려 역풍
-
10
李, 민주당 직격 “원수 싸우듯 하지말라…패싸움하면 되겠나”
트렌드뉴스
-
1
‘월급 50만원, 아파트는 4억’ 베트남…청년들 “그냥 평생 월세 살란다”[딥다이브]
-
2
한동훈 “2030년 정권 되찾겠다…2028년 총선 ‘보수 다수당’ 목표”
-
3
내년 환갑이지만…“근육운동 덕분에 은퇴 뒤 설계까지 끝내”[양종구의 100세 시대 건강법]
-
4
‘멸공라떼’ 내놓은 대전 카페, 태극기 잘못 그려…건곤감리 틀려 역풍
-
5
‘집회가요, 지도부, 인쇄물’ 없는 이런 시위는 처음 본다[청계천 옆 사진관]
-
6
“이화영 유죄, 李정권 ‘무고의 굿판’ 끝…민주당 사과해야” 野 맹공
-
7
“내 신청곡 왜 취소해” 소주병으로 머리 내려친 70대 산악회원
-
8
李 조작기소 특검 발단 “연어 술파티”…법원 판단은 “거짓말”
-
9
“1000만원 줄 테니 나가달라”…집주인 제안, 받아도 될까 [집과법]
-
10
반도체→부동산 ‘富의 이동’ 원천차단?…‘보유-양도세’ 꺼낸 김용범
-
1
[단독]노태악, 선관위서 수당 4년간 1.8억 받아…3배 ‘셀프 증액’도
-
2
위기때면 단식-입원, ‘소나기’ 피하는 장동혁
-
3
李 조작기소 특검 발단 “연어 술파티”…법원 판단은 “거짓말”
-
4
李 “선관위 원포인트 개헌, 필요땐 대통령 발의”
-
5
한동훈 “2030년 정권 되찾겠다…2028년 총선 ‘보수 다수당’ 목표”
-
6
“투표지 축소 인쇄 보고 못받았다”던 노태악, 뒤늦게 말바꿔
-
7
李 “우리 돈으로 우리 방위 책임질건데, 전작권 왜 美가 갖나”
-
8
李 “우리 돈으로 방위 책임, 전작권 왜 美가 갖나”
-
9
‘멸공라떼’ 내놓은 대전 카페, 태극기 잘못 그려…건곤감리 틀려 역풍
-
10
李, 민주당 직격 “원수 싸우듯 하지말라…패싸움하면 되겠나”
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개



댓글 0