공유하기
[신문과 놀자!/어린이과학동아 별별과학백과]시공간 제약없는 가상인간, 어떻게 진짜 사람처럼 보일까요?
- 동아일보
-
입력 2022년 5월 13일 03시 00분
글자크기 설정
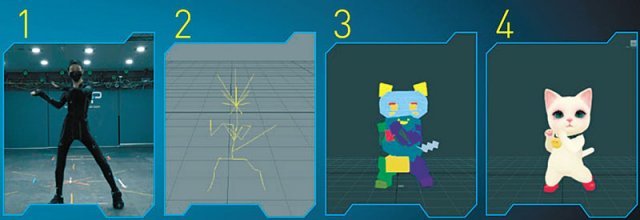
자연스러운 동작 위해 모션 캡처 사용, 배우 몸에 여러 개의 마커 부착
전용 카메라로 움직임 데이터 기록… 말소리 글자로 변환하는 과정인 STT
글자를 목소리로 바꾸는 TTS 거치면 대화하는 것처럼 의사소통 가능
소셜미디어 인플루언서, 모델, 가수, 쇼호스트, 기상캐스터…. 이 모든 일을 동시에, 어디에서나 할 수 있는 사람이 있을까요? 보통 사람이라면 불가능해 보이는 이 미션을 해결해 내는 존재가 있습니다. 바로 ‘가상 인간’입니다.
○시공간의 제약 없는 가상인간의 세계
2020년 일본에서는 ‘이마’라는 가상 인간이 가구 기업 이케아의 한 매장에서 먹고 자며 생활하는 영상을 통해 광고 모델로 활동했어요. 그 모습이 너무 자연스러워서 많은 사람이 진짜 사람인 줄 알았다는 반응을 보였지요. 일본의 이마뿐 아니라 우리나라의 ‘로지’, ‘루이’ 등 현재 활동하고 있는 가상 인간들을 보세요. 주의 깊게 관찰하지 않으면 이들이 진짜 사람이 아니라는 사실을 알아채기가 어렵습니다. 가상 인간이 처음부터 이렇게 감쪽같았던 건 아니에요. 20여 년 전 우리나라에 등장한 1호 가상 인간이자 사이버 가수인 ‘아담’을 보면 실제 사람과는 거리가 멀죠. 현재 가상 인간은 활발하게 경제 활동도 합니다. 지난해 집계된 자료에 따르면 우리나라의 가상 인간 로지는 광고 모델 활동으로 2020년 한 해 동안 약 10억 원의 수익을 올렸습니다. 인스타그램에서 300만 팔로어를 가진 미국의 가상 인플루언서 ‘릴 미켈라’는 같은 해에 무려 130억 원에 달하는 수익을 낸 것으로 알려졌어요.
가상 인간은 시공간의 제약을 받지 않습니다. 세계 어디에서나 동시에 존재하며 서로 다른 일을 할 수 있고, 나이도 먹지 않죠. 동국대 철학과 심지원 교수는 “가상 인간은 실제 연예인과 달리 건강이나 과거사 등 개인적인 문제를 일으킬 가능성이 적고, 동시에 여러 가지 일을 할 수 있는 등 효율적인 특징이 있어 기업들이 광고 모델로 선호하는 것”이라고 설명했어요. 가상 공간의 규모가 커지면서 가상 인간의 활동은 앞으로 더욱 활발해질 거예요.
○생동감 주는 모션 캡처로 탄생하는 가상 인간

○가상 인간과 어떻게 소통할까
아무리 사람과 똑같이 생겼더라도 가상 인간과 제대로 말이 통하지 않는다면 사람처럼 느껴지지 않을 거예요. 음성 대화는 사람의 가장 자연스러운 소통 방식이기 때문이죠. 우리가 가상 인간에게 대답을 듣기까지 가상 인간은 어떤 과정들을 거치는 걸까요? 가상 인간에 탑재된 인공지능이 사람의 말소리를 이해하기 위해서는 먼저 말소리를 글자로 변환하는 과정이 필요합니다. 이 과정을 ‘STT(Speech to Text)’라고 합니다. 마이크 같은 센서가 사람의 말소리를 인식하면, 인공지능이 소리의 파형을 분석해 글자와 단어로 옮겨요. 인공지능은 이 글자와 단어들을 기존 언어 데이터와 비교하고 처리해 최종적으로 문장을 재구성하지요. 인공지능이 언어 데이터를 많이 학습할수록 문장이 매끄러워져요.
사람이 어떤 말을 했는지 파악했으니, 이제 가상 인간이 어떻게 대답할지 결정해야 합니다. 인공지능을 활용한 언어 생성 모형은 수많은 대화 예시를 학습해서 사람이 건넨 말에 대한 가장 적절한 대답을 고릅니다. 가상 인간의 성격에 따라 특정한 말투를 사용해 말할 수도 있지요.
가상 인간이 뭐라고 대답할지 결정했다면, 이 문장을 다시 목소리로 바꾸어야 합니다. 이 과정은 글자를 음성으로 변환한다는 뜻에서 ‘TTS(Text to Speech)’라고 불러요. 대화할 때 나올 수 있는 모든 문장을 미리 녹음할 수는 없으니 어떤 글자가 나오더라도 이를 음성으로 나타낼 수 있는 음성 합성 기술이 필요합니다. 여러 가지 문장을 읽어 음성을 녹음한 뒤, 이 음성을 글자, 단어 등의 단위로 쪼개어 저장합니다. 그러면 어떤 문장이라도 저장된 음성 단위를 합쳐서 표현할 수 있죠.
© dongA.com All rights reserved. 무단 전재, 재배포 및 AI학습 이용 금지
트렌드뉴스
-
1
사우디의 선견지명…‘이란 리스크’ 대비해 1000㎞ 송유관 건설
-
2
트럼프 ‘호르무즈 나몰라라’ 하루뒤 “안열면 석기시대 되게 폭격”
-
3
‘캐리어 시신’ 사위 “장모가 시끄럽고 물건정리 안해 때렸다”
-
4
[단독]국빈 방한 인니 대통령, KF-21 전투기로 호위 무산
-
5
[속보]트럼프 “한국, 도움 안됐다”…주한미군 거론하며 파병 안한데 불만
-
6
‘대구 캐리어 시신’ 사위 “장모가 소음을 내서 폭행”
-
7
‘탱크 탑승’은 후계의 상징…김정은 26세, 주애는 13세에 올라[청계천 옆 사진관]
-
8
태권도 시범 본 인니 대통령 “우리 쁜짝실랏과 비슷”
-
9
민간차량 8일부터 ‘공영주차장 5부제’… 홍해로 원유수송 검토
-
10
공영주차장 8일부터 ‘5부제’ 시행…공공기관은 ‘홀짝제’
-
1
안철수 “세금 90% 내는데 지원금 제외되는 30% 국민 있다”
-
2
[단독]尹 영치금 12억 넘었다…대통령 연봉의 4.6배
-
3
정원오 42.6% vs 오세훈 28.0%… 전재수 43.7% vs 박형준 27.1%
-
4
정원오-박주민, 오세훈에 석달새 오차내서 10%P대 우위로
-
5
국힘 “정원오는 미니 이재명” 與 “법적대응”…칸쿤 출장 의혹 공방
-
6
“술-식사뒤 15명에 대리비 68만원 줬다가 회수” 김관영 CCTV 보니…
-
7
“종량제 봉투, 코로나때 마스크처럼 구매 제한 검토”
-
8
장동혁 “재판장이 국힘 공관위원장 하시라…법원, 너무 깊이 정치개입”
-
9
호르무즈 막혀도 느긋한 中…“우린 에너지 밥통 차고 있다”
-
10
국힘 새 공관위원장에 4선 박덕흠 의원
트렌드뉴스
-
1
사우디의 선견지명…‘이란 리스크’ 대비해 1000㎞ 송유관 건설
-
2
트럼프 ‘호르무즈 나몰라라’ 하루뒤 “안열면 석기시대 되게 폭격”
-
3
‘캐리어 시신’ 사위 “장모가 시끄럽고 물건정리 안해 때렸다”
-
4
[단독]국빈 방한 인니 대통령, KF-21 전투기로 호위 무산
-
5
[속보]트럼프 “한국, 도움 안됐다”…주한미군 거론하며 파병 안한데 불만
-
6
‘대구 캐리어 시신’ 사위 “장모가 소음을 내서 폭행”
-
7
‘탱크 탑승’은 후계의 상징…김정은 26세, 주애는 13세에 올라[청계천 옆 사진관]
-
8
태권도 시범 본 인니 대통령 “우리 쁜짝실랏과 비슷”
-
9
민간차량 8일부터 ‘공영주차장 5부제’… 홍해로 원유수송 검토
-
10
공영주차장 8일부터 ‘5부제’ 시행…공공기관은 ‘홀짝제’
-
1
안철수 “세금 90% 내는데 지원금 제외되는 30% 국민 있다”
-
2
[단독]尹 영치금 12억 넘었다…대통령 연봉의 4.6배
-
3
정원오 42.6% vs 오세훈 28.0%… 전재수 43.7% vs 박형준 27.1%
-
4
정원오-박주민, 오세훈에 석달새 오차내서 10%P대 우위로
-
5
국힘 “정원오는 미니 이재명” 與 “법적대응”…칸쿤 출장 의혹 공방
-
6
“술-식사뒤 15명에 대리비 68만원 줬다가 회수” 김관영 CCTV 보니…
-
7
“종량제 봉투, 코로나때 마스크처럼 구매 제한 검토”
-
8
장동혁 “재판장이 국힘 공관위원장 하시라…법원, 너무 깊이 정치개입”
-
9
호르무즈 막혀도 느긋한 中…“우린 에너지 밥통 차고 있다”
-
10
국힘 새 공관위원장에 4선 박덕흠 의원
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개

![[김도연 칼럼]인간을 대신하는 AI, 문명 전환은 이미 시작됐다](https://dimg.donga.com/a/464/260/95/1/wps/NEWS/FEED/Donga_Home_News2/133658179.1.thumb.jpg)

댓글 0