공유하기
AI 하드웨어 생태계의 시작이자 기준, 'MLPerf'란 무엇인가?
- 동아닷컴
-
입력 2024년 4월 4일 16시 18분
글자크기 설정

이외에도 구글, 퀄컴, 에이수스, 델, 기가바이트 등을 포함한 총 23개의 기관 및 기업이 v4.0 테스트에 참여했으며, 약 8500개 결과와 900여 개의 전력 소모량 포함 결과가 게재됐다. 퀄컴이 지난해 11월 선보인 ‘클라우드 AI 100 울트라’ 결과나 레드헷-슈퍼마이크로의 통합 제품도 주목을 받았다. 갈수록 MLPerf 기반의 경쟁이 첨예해지는 배경은 무엇이며, 일반 대중 입장에서는 이를 어떻게 인식해야 할까?
MLPerf, AI 하드웨어의 기준점
ML커먼스는 ‘모두를 위한 더 나은 AI’를 목표로 MLPerf같은 업계 표준을 제시하며, 기계학습 시스템과 소프트웨어, 솔루션이 투명하게 경쟁하는 무대를 마련하고, 새로운 기능 공유 및 AI 애플리케이션의 토대를 마련한다. 또 세계 최대 공공 음성-텍스트 변환 데이터 세트를 구축하거나, 서로 다른 인프라 및 세계 전역의 AI 개발자들이 공유하는 기계학습 모델도 구성한다. 2018년 첫 벤치마크 출시 이후 현재까지 4만7000여 개의 결과가 도출됐고, 125개 이상의 회원 및 계열사가 속해있다.
미로 호닥(Miro Hodak) AMD AI/ML 선임 솔루션 아키텍트 겸 MLPerf 추론 부문 공동 의장은 "MLPerf는 협업을 통해 만들어진 도구다. 다양한 칩 및 하드웨어 공급 업체로부터 성능 결과를 받아 데이터베이스를 만들고, 잠재적 구매자가 다양한 하드웨어 유형의 성능을 평가할 수 있다. AI 작업이 진행 상황과 성능 등 수많은 매개변수의 영향을 받는다는 점을 고려하면, MLPerf가 특정 작업에 대한 사실상 표준이 되는 경우가 많다"라고 첨언했다.

MLPerf같은 표준 성능 지표가 필요한 이유는 AI 반도체의 비교 평가가 어렵기 때문이다. AI 반도체는 AI 모델을 학습하고, 대규모 데이터 세트를 처리하는 학습용(Training) 반도체와 특정 AI 모델로 예측 결과를 출력하는 추론용(Inference) 반도체로 나뉜다. 여기까지는 쉽게 구분되나, 조건이 조금만 달라도 구분이 어렵다. 연산 성능과 처리 방식, 모델, 명령어, 데이터의 품질과 분량 등 변수에 따라 결과가 다르고, 심지어 동일한 파일과 코드를 활용해도 확률 차이로 인해 결과가 달라진다.
시스템 성능과 기계학습 모델 구축 능력을 보는 MLPerf:학습
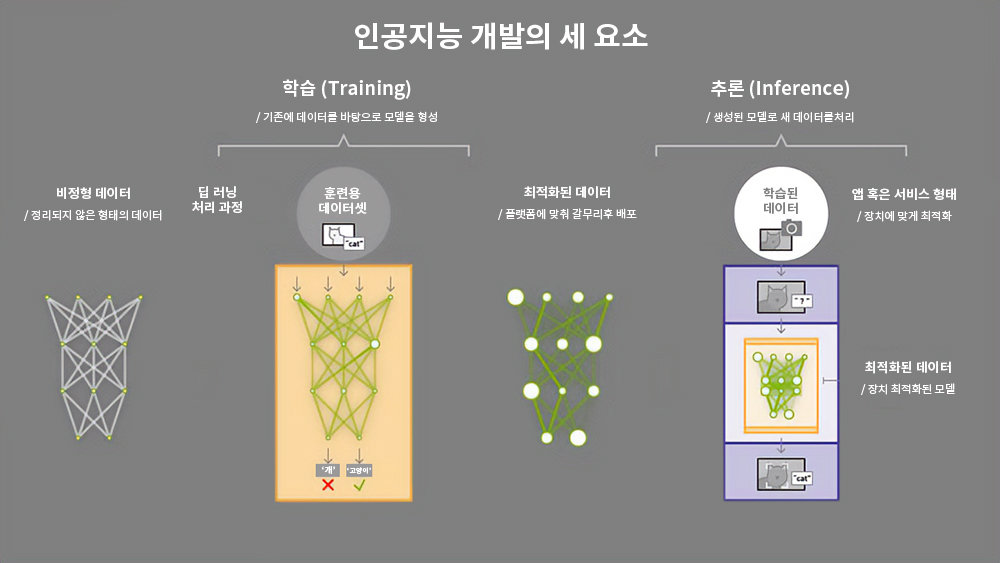
AI 개발은 학습, 최적화, 추론 세 단계로 진행된다. 학습 단계는 모델이 데이터를 활용해 스스로 학습하고 개선하는 절차다. 학습된 모델은 활용에 따라 장치에 맞게 분산하거나, 데이터 품질을 끌어올리는 최적화 과정을 거치고, 최적화가 끝나면 실제 환경에서 원하는 결과를 처리하는 추론으로 진입한다. MLPerf의 테스트는 학습, 그리고 추론에 초점을 맞춘다.
MLPerf 테스트는 메모리, 저장장치, 상호연결 등이 검증된 시스템을 활용하며, ML커먼즈가 제시한 참조 사항과 전처리, 모델, 교육 방법 및 품질을 그대로 활용한 폐쇄 테스트와 임의의 훈련 데이터 및 전처리 등을 사용해도 되는 개방형 테스트가 있다. 폐쇄 테스트는 숫자 형식도 FP32(단정도 부동소수점), FP16(반정밀도 부동소수점), TF32, bfloat16, int8(정수), int4 등으로 정해져있어서 이기종 간 결과를 비교하기 좋고, 반대로 개방형은 모든 형식과 크기가 자유로워서 장치의 이상적 성능을 확인하기 좋다.
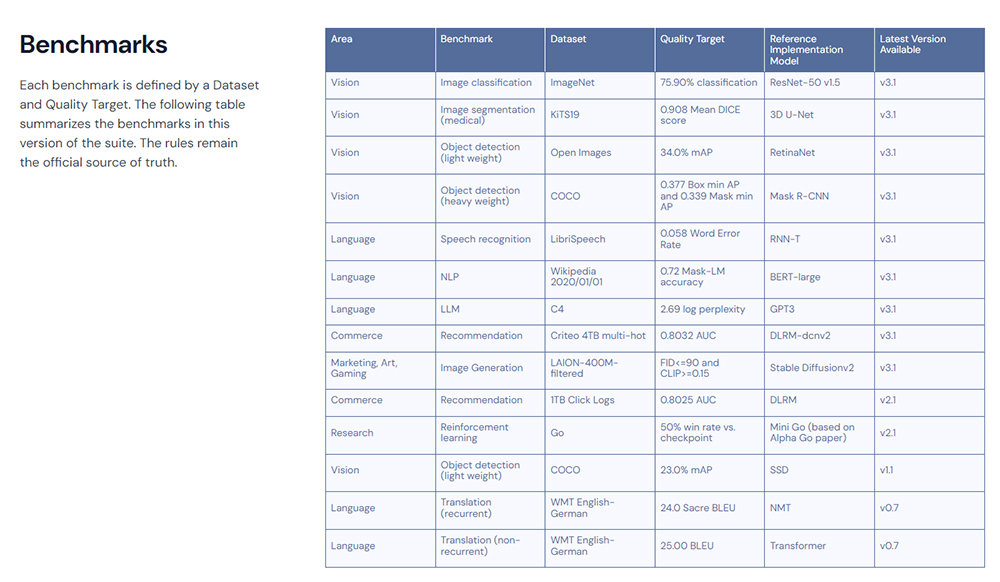
MLPerf 학습은 시스템이 얼마나 빠르게 기계학습 모델을 구축하는지 측정하고, 그 속도를 비교한다. 테스트 항목은 이미지 분류, 의료용 이미지 분할, 물체 감지 경량 및 중량, 음성 인식, 자연어 처리, 대형 언어모델(LLM), 상업적 추천 등 9개 항목으로 진행한다. v3.0 부터는 GPT-3 활용이 추가됐고, v3.1 버전에는 스테이블 디퓨전 v2를 활용한 이미지 생성형 AI 처리도 포함됐다. 결과는 확률적으로 느린 실행과 빠른 실행 값을 제외한 값을 정규화한다.

엔비디아가 제출한 MLPerf v3.1 학습 결과를 살펴보자. 엔비디아는 훈련 항목에 H100 80GB GPU 1만 752대와 인텔 제온 플래티넘 8462Y+ CPU 2688대로 구성된 엔비디아 EOS 슈퍼컴퓨터를 제출했다. 그 결과 엔비디아 EOS는 1750억 개의 매개변수로 구성된 GPT-3 모델 기반 테스트를 6개월 전 결과인 10분 50초보다 3배 빠른 3분 50초만에 끝냈다. 해당 결과는 업계 관계자나 결정권자에게 ‘1만 대의 엔비디아 H100 GPU’로 구성된 시스템의 예상 성능과 비례 구성시 성능, 그리고 비용 대비 효율을 가늠하는 잣대가 된다.
대규모 작업에 대한 성능을 확인하는 작업인 만큼 GPU 8대 구성의 랙(Rack)부터 1만 대 단위의 데이터 서버가 테스트에 참여하며, 현재 19개 조직 200개 이상의 결과가 게재돼 있다. 각 데이터의 시스템 구성이 달라서 상호 비교는 어렵지만, 이마저 없다면 AI 컴퓨터 성능의 갈피조차 잡을 수 없다. MLPerf 학습 결과는 이미지 생성 및 컴퓨터 비전 대응 분야나 대규모 언어 모델 구축, 금융 모델 등 데이터 분석, 의료 이미지 분석 등의 분야에서 주로 참고된다.
사전 제공 모델로 성능을 판단하는 MLPerf:추론
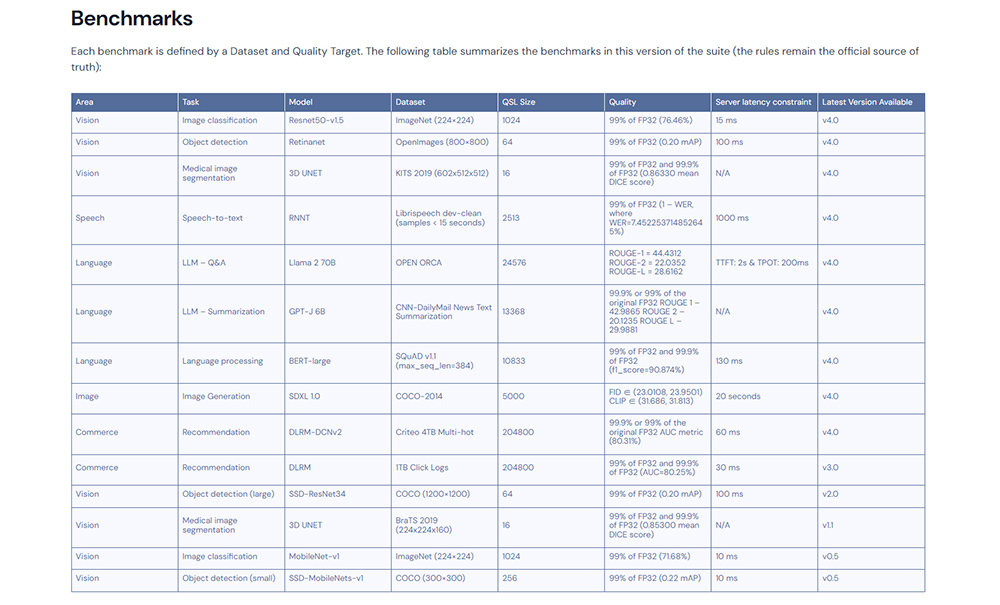
MLPerf 추론은 시스템이 다양한 배포 시나리오에서 얼마나 AI 및 기계학습을 빨리 수행하는지를 측정한다. 기존 추론 테스트는 이미지 분류, 객체 감지, 의료영상 분할, 음성 텍스트 전환, 자연어 처리, 대규모 언어 모델, 상업 추천이 있었고, 최신 버전인 MLPerf 추론 v4.0부터 700억 개 매개변수가 포함된 메타 Llama2-70B LLM과 텍스트-이미지 생성AI 모델 성능을 확인하는 스테이블 디퓨전 XL이 추가됐다. 시험 중 소요되는 전력 소모량 포함 결과 항목도 있다.
추론 테스트가 대규모 데이터 센터, 스마트폰용 칩인 모바일, 사물인터넷용 장치인 엣지, 개발자용 키트 및 시스템 온 칩(SoC), 웨어러블, 센서 등 초소형(Tiny) 4개 항목으로 나뉘는 이유는 실제로 AI를 활용하는 장치에서의 성능을 구분하기 위해서다. 개발자들은 4개 규격에 대한 결과를 토대로, 각 플랫폼에 AI 모델을 도입하면 어느정도 성능을 낼 수 있는지 짐작할 수 있다.
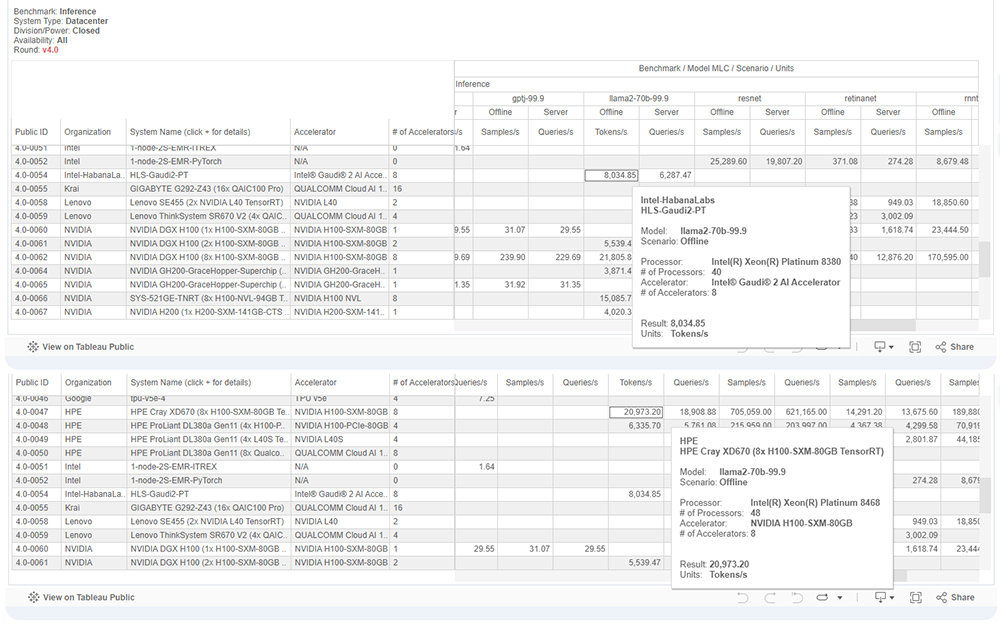
인텔이 지난 3월 29일 발표한 MLPerf v4.0 결과로 MLPerf 추론 결과를 살펴보자. 인텔은 가우디 2 AI 가속기 8대와 인텔 제온 플래티넘 8380 40대로 구성된 시스템으로 LLama 2-70B 및 스테이블 디퓨전 XL 두 개에 참여했다. 그 결과 Llama 2는 오프라인에서 초당 8034 토큰, 서버 조건에서 초당 6287쿼리를 전송했다. 스테이블 디퓨전 XL은 오프라인에서 초당 6.26매의 샘플, 서버로는 6.25쿼리를 제공했다.
엔비디아 H100 4대와 인텔 제온 플래티넘 8468 48대로 구성된 HPE 크레이 XD670이 Llama 2 오프라인에서 초당 2만 973토큰, 스테이블 디퓨전 XL에서 오프라인 초당 13.16매인 점과 비교하면 절반 성능이지만, 중요한 것은 우열을 가리는 게 아니다. ‘8대의 가우디 2와 40대의 CPU로 구성된 시스템이면 4대의 엔비디아 H100 및 48대 CPU 시스템보다는 성능이 높겠구나’와 ‘HPE 크레이 XD670에 H100 8대 구성이면 이정도 성능이구나’를 알 수 있다.
미로 호닥 MLPerf 추론 부문 공동 의장은 "MLPerf 결과는 AI 모델 및 기술의 표준화, 성능 평가에 대한 해답을 빠르게 제공하고, 그 결과는 현장의 성과 향상을 명확히 담는다"라면서, "일반 대중의 입장에서는 자신이 사용하는 애플리케이션을 대규모로 사용하는 시스템이 표준화하고, 성능이 나아지는 것에 대한 혜택을 누리고 있다"라고 생각하면 된다고 답했다.
고성능 컴퓨팅도 중요, AI PC용 벤치마크도 등장 예정
추가로 주목할 항목은 MLPerf 학습의 고성능 컴퓨팅(HPC) 부문, 그리고 올해 공개될 클라이언트 작업 부문이다. HPC는 기후 대기천 식별, 우주론 매개변수 예측, 양자 분자 모델링 및 단백질 구조 예측을 포함한 네 가지 과학 컴퓨팅 사용 사례 등 첨단 과학 분야용 시스템을 평가하기 위해 사용된다.

아직까지 비교 결과가 약 30개 정도로 적지만, HPC v3.0 버전부터 세계 최대 슈퍼컴퓨터를 보유한 조직 8곳의 결과도 포함됐다. 장기적으로는 TOP500 슈퍼 컴퓨터를 객관적으로 대체할 수 있는 수단으로 평가된다. 또한 버전 업데이트에 따라 현 세대 슈퍼컴퓨터의 성능을 변별력있게 분석할 수 있다. 예를 들어 기후 대기천 식별 모델링은 v2.0과 v3.0 사이에 처리 성능이 14배 빨라졌다.
클라이언트 작업 항목은 인텔 코어 울트라, AMD 라이젠 AI 엔진, 퀄컴 스냅드래곤 X 엘리트 등 마이크로소프트 윈도우 기반 AI PC의 성능을 평가하기 위한 표준 벤치마크다. 테스트는 AI 기반 소프트웨어는 물론 Llama 2 처리 품질 및 성능 균형, 안전 문제 등을 확인하는 내용이 담길 예정이다.
미로 호닥 MLPerf 추론 부문 공동 의장은 "클라이언트별 벤치마크 및 측정 작업을 수행하는 클라이언트 실무그룹을 이제 막 시작했으며, 초기 단계에 있다. 올해 말에는 진행 상황을 발표할 예정이고, 벤치마크는 아직 사양을 구성하는 단계라 구체적으로 답변을 할 수 없다"라고 말했다.
상대 평가와 성능 추측을 위한 기준, 시장 경쟁력과 직결
결론적으로 MLPerf는 기계 학습 모델의 구축 및 활용 성능을 정량 평가하는 기준이며, 산업 현장에서 구축하려는 AI 시스템의 성능을 예측, 비교하는 데 쓰인다. 기업 입장에서 MLPerf 결과를 소개하는 것은 시스템 성능이 입증되었음을 보여주고, 더 나아가 AI 시장에 신뢰할 수 있는 제품을 공급하겠다는 의미가 된다. 엔비디아 쿠다처럼 제품의 AI 생태계도 중요한 요소지만, 최소한의 관문은 넘은 셈이다.
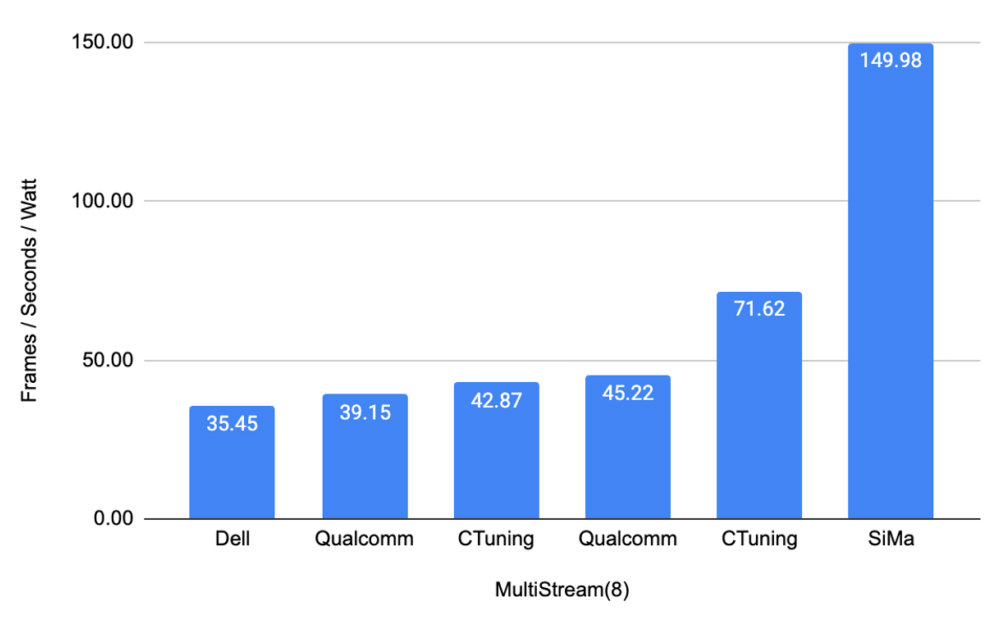
엔비디아의 대안을 노리는 시장에서는 MLPerf 경쟁이 더욱 치열하다. 미국의 기계학습 SoC 제조사 시마(SiMa.ai)는 지난 3월 27일 공개된 MLPerf : 추론 엣지컴퓨팅, 전력-폐쇄형 부문에서 퀄컴, 델의 제품과 비교해 훨씬 우수한 초당 프레임 전력 효율을 기록했다. 시마 SoC가 동일 전력에서 150프레임을 처리할 때, 타사 제품들은 약 35~71프레임을 처리했다. ‘ResNet 모델용 고효율 AI 엣지 반도체’라는 조건이 맞는 기업이라면 솔깃한 내용이다.
퓨리오사AI, 사피온, 리벨리온, 딥엑스 등 주요 신경망 처리 장치(NPU) 기업들이 MLPerf 결과를 확보하는 이유도 시마의 사례와 같은 맥락이다. 엔비디아와 직접 경쟁하기보다는, 특정 항목에 대해 엔비디아의 대체제가 될 수 있음을 보여주기 위함이다. 국내 AI 반도체 3사 중 하나인 퓨리오사AI는 아시아 스타트업으로는 유일하게 ML커먼스 창립 멤버며, 익히 그 중요성을 인지해 전략을 구상해왔다.

정영범 퓨리오사AI 이사는 “NPU 기업들이 홈페이지에 게재하는 성능은 칩 수량, 서버 성능, 소모 전력, 구매 단가 등을 종합해서 살펴야 한다. 하지만 MLPerf 결과는 공정한 절차를 거치며, 전 세계 업계에서 통용돼 그 중요성이 대단하다”라면서, “퓨리오사AI도 이미 1세대 NPU는 테스트를 거쳤고, 2세대 NPU 레니게이드(RNGD) 준비가 끝나면 소프트웨어 및 하드웨어 최적화를 거쳐 9월 중에는 새 MLPerf 결과를 발표할 예정”이라고 말했다. MLPerf 결과만 잘 나오면 시장의 스포트라이트는 자연스레 집중될 것이다.
MLPerf가 있기에 AI 시장도 빨리 성장할 수 있다. 상대 평가가 안되면 제품 성능도 구분할 수 없고, 시스템 구성도 예측하기 어려워 시장 자체가 보수적이었을 것이다. 실제로 일반 사용자용 PC 시장은 UL솔루션즈의 3D마크, PC마크, 맥슨 시네벤치로 개별 PC 성능을 비교할 수 있고, 소비자들이 시스템을 비교했기 때문에 각 제조사들이 경쟁하며 시장이 커왔다. AI 컴퓨팅 산업도 크게 다르지 않으며, MLPerf가 있기에 시장 경쟁이 이뤄지고 있다. 앞으로도 기업들은 MLPerf를 기준으로 발전하고, 더 나은 성능과 전력 효율을 내기 위해 개발을 이어나갈 것이다.
미로 호닥 MLPerf 추론 부문 공동 의장은 "AI 분야는 빠르게 발전하고 있다. 몇 년 전 강조됐던 합성곱신경망은 LLM을 구축하는 장치로 자리를 내주었다. 이 사례를 통해 업계에서는 다양한 AI 모델과 기술의 표준화, 성능 평가에 대한 필요성이 제기됐고, ML커먼스가 MLPerf를 통해 그 역할을 하고 있다"라면서, "ML커먼스는 서로 경쟁하면서도 성능 평가를 위한 도구를 개발하기 위해 AI 시장의 주요 업체들의 기술 역량을 한자리에 모은 컨소시엄이다. 이를 통해 현장의 성능 향상에 대한 명확성을 제공하고, 전체 AI 생태계에 이익을 가져다준다"라고 말했다.
동아닷컴 IT전문 남시현 기자 (sh@itdonga.com)
트렌드뉴스
-
1
“이란, 중국 무기로 美 F-15E 전투기 격추했을 가능성 높아”
-
2
“코 스프레이 2번 뿌렸더니 기억력 쑥”…치매 치료 가능성 [노화설계]
-
3
사촌 신분증으로 사전투표…지문 인식서도 안 걸러져
-
4
“언니 따라 갔던 대학”… 네 자매 인생 바꾼 서정대의 배움
-
5
국힘, “1번만 찍었다” 공개한 이해식 고발…선관위 “위반 아냐”
-
6
트럼프 “이란 핵 개발·구매 모두 포기…매우 좋은 합의 가까워져”
-
7
美건국 250주년 공연에 가수들 보이콧…트럼프 “내가 대신할 것”
-
8
MB는 부산서 국밥 먹고, 박근혜는 대구 서문시장 찾았다
-
9
‘삼전닉스 ±2배’ 5조 돌파…매수-매도 3~5일내 승부봐야
-
10
이영지, 빨간 머리·옷 사진 올렸다가 사과…“경솔한 행동 죄송”
-
1
호남 간 정청래 “윤·이·박 돌아다녀…김대중 벌떡 일어날 일”
-
2
李 “투표 포기는 국민 속이는 자에게 기회주는 것”
-
3
돼지국밥 먹은 MB ‘친이’ 박형준 지원…정청래 “윤·이·박 돌아다녀”
-
4
이영지, 빨간 머리·옷 사진 올렸다가 사과…“경솔한 행동 죄송”
-
5
장동혁 “투표 포기하면 이재명 범죄 지울 기회 주는 것”
-
6
美건국 250주년 공연에 가수들 보이콧…트럼프 “내가 대신할 것”
-
7
국힘, ‘기표소 논란’ 李 선거법 위반 혐의 고발
-
8
반도체로 부유해진 대만 경제의 그림자: 대만병과 거지 슈퍼맨 [딥다이브]
-
9
정원오 “무능 심판” vs 오세훈 “정권 심판”…서울시장 마지막 주말 총력전
-
10
‘韓은 中에 단검’ 발언 브런슨 “작전 환경 설명한 것” 해명
트렌드뉴스
-
1
“이란, 중국 무기로 美 F-15E 전투기 격추했을 가능성 높아”
-
2
“코 스프레이 2번 뿌렸더니 기억력 쑥”…치매 치료 가능성 [노화설계]
-
3
사촌 신분증으로 사전투표…지문 인식서도 안 걸러져
-
4
“언니 따라 갔던 대학”… 네 자매 인생 바꾼 서정대의 배움
-
5
국힘, “1번만 찍었다” 공개한 이해식 고발…선관위 “위반 아냐”
-
6
트럼프 “이란 핵 개발·구매 모두 포기…매우 좋은 합의 가까워져”
-
7
美건국 250주년 공연에 가수들 보이콧…트럼프 “내가 대신할 것”
-
8
MB는 부산서 국밥 먹고, 박근혜는 대구 서문시장 찾았다
-
9
‘삼전닉스 ±2배’ 5조 돌파…매수-매도 3~5일내 승부봐야
-
10
이영지, 빨간 머리·옷 사진 올렸다가 사과…“경솔한 행동 죄송”
-
1
호남 간 정청래 “윤·이·박 돌아다녀…김대중 벌떡 일어날 일”
-
2
李 “투표 포기는 국민 속이는 자에게 기회주는 것”
-
3
돼지국밥 먹은 MB ‘친이’ 박형준 지원…정청래 “윤·이·박 돌아다녀”
-
4
이영지, 빨간 머리·옷 사진 올렸다가 사과…“경솔한 행동 죄송”
-
5
장동혁 “투표 포기하면 이재명 범죄 지울 기회 주는 것”
-
6
美건국 250주년 공연에 가수들 보이콧…트럼프 “내가 대신할 것”
-
7
국힘, ‘기표소 논란’ 李 선거법 위반 혐의 고발
-
8
반도체로 부유해진 대만 경제의 그림자: 대만병과 거지 슈퍼맨 [딥다이브]
-
9
정원오 “무능 심판” vs 오세훈 “정권 심판”…서울시장 마지막 주말 총력전
-
10
‘韓은 中에 단검’ 발언 브런슨 “작전 환경 설명한 것” 해명
-
- 좋아요
- 0개
-
- 슬퍼요
- 0개
-
- 화나요
- 0개



댓글 0