
AI semiconductors are not an alternative to GPUs, but a new direction... Differentiating LPU by new approach to memory.
AI semiconductors are not an alternative to GPUs, but a new direction... Differentiating LPU by new approach to memory.
Posted September. 23, 2025 09:38,
Updated September. 23, 2025 09:54
- HyperAccel, founded by Joo-Young Kim, is developing AI semiconductors
optimized for inference, focusing on memory efficiency and low power
consumption.
- Their FPGA-based LPU (LLM Processing Unit) products have been sold to
national research institutes, and they are currently working on their
next-generation product, Bertha.
- HyperAccel aims to provide cost-effective and high-performance solutions for AI
nference, targeting a heterogeneous semiconductor market that combines
GPUs, NPUs, LPUs, and DPUs.
"No matter how well AI semiconductors are designed, they are worthless if not used in actual workloads. In addition, it is important to perform well in real services and work and not just standardized benchmarks. HyperAccel has been working closely with services companies, especially Naver Cloud, from the semiconductor design stage to create semiconductors that work well for actual services, and is developing software tools for the real-world environment through emulators."
In order for a good tool to shine, it takes a skilled craftsman. If either of the two is not at the same level, it is difficult to achieve results, which is the trend of today's artificial intelligence (AI) market. Joo-Young Kim, CEO of HyperAccel, is a person who makes 'a good tool for skilled craftsmen'. He is a professor at the Department of Electrical and Electronic Engineering at KAIST and founded HyperAccel in January 2023.

He worked at Microsoft Research and Microsoft Cloud Azure starting in 2010 and witnessed the changes AI semiconductors bring to the world. Since 2019, he has been involved in academia and has been interested in the impact of transformer models on the AI industry, and after developing processor technology optimized for transformer inference calculations, he succeeded in building prototypes with FPGAs (programmable semiconductors). Then, when ChatGPT appeared in 2022, he had a vision of the emergence of the semiconductor market for inference and founded HyperAccel. AMD, in particular, saw the FPGA-based prototypes and proposed a joint development, and this led to entering the market with more confidence.
Hear directly from CEO Joo-Young Kim about the LPU semiconductor for large language models (LLMs)
Since its founding in 2023, HyperAccel has launched Orion, which is an FPGA-based LPU (LLM Processing Unit) and is currently in the midst of developing its next-generation product Bertha. First, we asked about Orion’s introduction and achievements, as well as the progress of Bertha.
Joo-Young said, "The sales of FPGA-based LPU products were to national research institutes such as the Electronics and Telecommunications Research Institute of Korea (ETRI) and the Korea Electronics Technology Research Institute (KETI). FPGAs are provided under the condition of built-in operation due to the limited computing capacity, and in the second half of the year, we plan to jointly develop a service that combines software and hardware with Trustlab, which develops civil service AI services, and sell it to governments and institutions."

Next-generation semiconductors are products optimized for inference. Joo-Young said, "GPUs process data in parallel, which is advantageous for training operations to develop AI. The complexity of operations is also much more complex than inference. This area we cannot keep up with the GPU. However, inference, which obtains repeated results by adding new inputs to the trained model, requires more memory bandwidth utilization than computation. Therefore, we designed an LLM processing unit that considers memory efficiency."

He continued, "Bertha, the second-generation LPU, completed design in April of this year and will manufacture at Samsung Foundry using 4nm process thro
ugh the process of logic synthesis and chip placement on the substrate to implement the blueprint as a physical circuit. In the first half of next year, we will conduct a proof of concept (PoC) on Naver Cloud based on engineering samples, and after verification, we will start mass production from the second half of next year."
HyperAccel LPU: Optimized for Inference from the Ground Up
Although Nvidia's GPUs are still the trend in the AI industry, AI semiconductors at home and abroad are also expanding their adoption into the inference field. In particular, each semiconductor company is targeting its own market by presenting an optimized reasoning area. I asked about the design features of the HyperAccel LPU. Joo-Young said, "A GPU is a compute-oriented processing device that integrates numerous CUDA cores. It is a design that takes data, mounts it in chip memory, and calculates quickly through parallel calculations. It puts data into on-chip memory and writes and reads repeatedly," he said, explaining the basic design of GPUs.
He continued, "LPU is a processor that optimizes the amount of data movement per second that determines LLM inference performance. The LPU core with a proprietary technology called Streamlined Dataflow minimizes unnecessary movement of data. When model data is input to multiple LPU cores, each core produces inference results. Typical GPUs only support 50~60% of memory performance even after optimization, but LPUs achieve approximately 90% of maximum memory bandwidth. This is accomplished by applying a technology element called Streamlined Memory Access (SMA). SMA directly connects data fetched from external memory to the actual matrix and vector processors without bandwidth loss or data conversion."
Joo-Young likened the semiconductor AI processing to a factory to aid understanding. Semiconductor memory, which store data, can be thought of as a raw material warehouse. The logic die, composed of chips, is the actual assembly workshop. A GPU is like a massive factory with thousands of workers who can perform any task well. They handle everything from simple tasks like making teddy bears to complex manufacturing like assembling cars. However, all tasks must be performed sequentially, causing bottlenecks on the factory lines moving work from the GPU raw material warehouse to the workshop. In contrast, LPUs feature specialized production lines optimized for specific tasks, significantly reducing bottlenecks from raw materials to the workshop.
I thought HBM is the mainstream choice so why do you introduce LPDDR?
A notable aspect is the use of LPDDR5X, a low-power memory, rather than high-bandwidth memory (HBM). While the current trend in AI semiconductors is to adopt HBM for high-capacity memory, Bertha utilizes memory typically used in mobile devices. Joo-Young stated, “The reasons for incorporating LPDDR5X are threefold: securing high capacity, low-power performance, and stable supply and pricing. The NVIDIA H100 GPU uses 80GB HBM, while our LPU is planned to be equipped with 128GB LPDDR memory. To run a 60B (60 billion parameter) model, 120GB of memory is required. Using the H100 would necessitate two units, whereas the LPU can handle it with just one 128GB model."
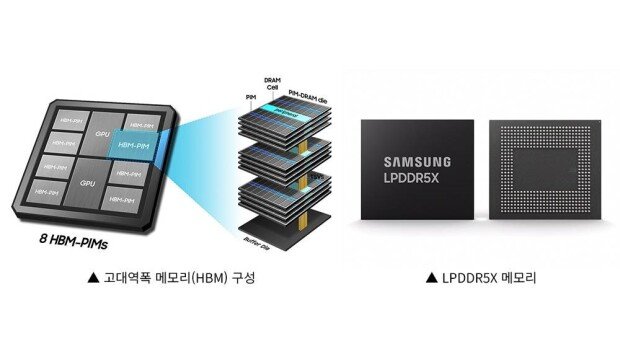
On the low power and demand side, "LPDDR is literally Low Power DDR memory, which consumes less power than HBM. Power consumption is a major factor in the operation of data centers from construction to operation. In addition, HBM has high demand and insufficient supply so there is potential for product delays and price increases due to demand-supply imbalances. On the other hand, LPDDR is widely used in industries other than semiconductors, making supply readily available and prices stable. In terms of cost, the price per 1GB is one-third to one-fifth the cost of HBM, and it does not require the latest manufacturing processes which also helps reduce future manufacturing costs."
He added, "LPDDR has many advantages, but it is relatively weaker in terms of transmission speed and bandwidth. We intend to overcome this limitation as much as possible with HyperAccel's LPU technology and processing efficiency (Batch) inventory to pursue a strategy to target the market with an economical price.”
Next-generation semiconductors are expected to be 10x more cost-effective and 5x higher performance per watt than GPUs
Whether AI semiconductors can substitute for GPUs is a question that has been presented to the industry as a whole. Orion, an FPGA server released by HyperAccel in 2023, achieved 1.33x higher energy efficiency than NVIDIA's H100 and 1.32x higher energy efficiency than L4, but now it needs to be updated with the emergence of Blackwell, which has higher performance. HyperAccel aims to stimulate the market with an 4nm ASIC scheduled for release next year.

Joo-Young stated, “The LPU ASIC semiconductor currently under development using Samsung's 4nm process supports various precision levels for quantization, including FP16, FP8, FP4, BF16, INT8, and INT4. While many technologies exist for quantizing model parameters, we are developing a technology that quantizes even the KV cache, which reuses computational information.” He added, “We expect the 4nm ASIC to achieve over 10x higher price-performance compared to GPUs and approximately 5x higher power-performance. This is the result of combining a streamlined dataflow architecture, the adoption of LPDDR5X instead of HBM, and an LPU engine specialized for LLM inference.”
HyperAccel's 4nm ASIC will support LLMs capable of multimodal analysis of complex audiovisual data, agent AI that automates decision-making processes, and Stable Diffusion. Future plans include deploying it as an on-device AI chip capable of operating independently without a network connection. Since the server product has already been designed, we expect rapid releases of on-device LLM prototypes utilizing the developed LPU engine.
Not overlooked is software support to increase utilization in the field going beyond just performance and efficiency. Joo-Young explained, “HyperDex is a comprehensive software system that includes a model parallelization layer for distributing models across multiple devices, a model mapper for converting each model to fit the device, an LPU compiler that generates instructions for the LPU to process model computations, and the device runtime and drivers necessary to run multiple LPUs.”
He continued, “The HyperDex SDK is compatible with all the latest software frameworks and can be integrated with any model registered on Hugging Face,” and added, “It also supports compilation using PyTorch, and we plan to provide SDKs from our partners this year to enable more people to use LPU computing.”
A heterogeneous semiconductor market that combines GPUs, NPUs, LPUs, and DPUs is on the horizon
As the next-generation semiconductor is scheduled to be released next year, this year will focus on development and product validation. However, work to secure use cases for AI semiconductors continues. Joo-Young stated, "Earlier this year, HyperAccel secured the overall project for the K-Cloud development initiative led by the Ministry of Science and ICT. This project involves implementing domestic AI as an actual data center service and achieving the world's third-highest ranking in the MLPerf inference energy efficiency category. While some argue that MLPerf focuses on hardware testing, which is detached from real service environments, it remains the most discriminative and credible test available. We will also collaborate with Naver Cloud to establish a test environment that measures AI semiconductor performance in actual service environments."
Finally, Joo-Young said, "We don't need to beat NVIDIA's GPU in every aspect. The future AI systems we envision will require heterogeneous semiconductor combinations that integrate specialized chips like GPUs, NPUs (Neural Processing Units), LPUs, and DPUs (Data Processing Units) to deliver optimal performance at optimal cost. While GPUs alone still dominate the market, the time will come when they must keep pace with other products. We will strive to establish HyperAccel's LPU as an indispensable solution in the heterogeneous computing environment and deliver on dramatically reducing the cost and power of existing computing platforms."
By Si-hyeon Nam (sh@itdonga.com)
optimized for inference, focusing on memory efficiency and low power
consumption.
- Their FPGA-based LPU (LLM Processing Unit) products have been sold to
national research institutes, and they are currently working on their
next-generation product, Bertha.
- HyperAccel aims to provide cost-effective and high-performance solutions for AI
nference, targeting a heterogeneous semiconductor market that combines
GPUs, NPUs, LPUs, and DPUs.
"No matter how well AI semiconductors are designed, they are worthless if not used in actual workloads. In addition, it is important to perform well in real services and work and not just standardized benchmarks. HyperAccel has been working closely with services companies, especially Naver Cloud, from the semiconductor design stage to create semiconductors that work well for actual services, and is developing software tools for the real-world environment through emulators."
In order for a good tool to shine, it takes a skilled craftsman. If either of the two is not at the same level, it is difficult to achieve results, which is the trend of today's artificial intelligence (AI) market. Joo-Young Kim, CEO of HyperAccel, is a person who makes 'a good tool for skilled craftsmen'. He is a professor at the Department of Electrical and Electronic Engineering at KAIST and founded HyperAccel in January 2023.
Joo-Young Kim, CEO of HyperAccel / source=IT dongA
He worked at Microsoft Research and Microsoft Cloud Azure starting in 2010 and witnessed the changes AI semiconductors bring to the world. Since 2019, he has been involved in academia and has been interested in the impact of transformer models on the AI industry, and after developing processor technology optimized for transformer inference calculations, he succeeded in building prototypes with FPGAs (programmable semiconductors). Then, when ChatGPT appeared in 2022, he had a vision of the emergence of the semiconductor market for inference and founded HyperAccel. AMD, in particular, saw the FPGA-based prototypes and proposed a joint development, and this led to entering the market with more confidence.
Hear directly from CEO Joo-Young Kim about the LPU semiconductor for large language models (LLMs)
Since its founding in 2023, HyperAccel has launched Orion, which is an FPGA-based LPU (LLM Processing Unit) and is currently in the midst of developing its next-generation product Bertha. First, we asked about Orion’s introduction and achievements, as well as the progress of Bertha.
Joo-Young said, "The sales of FPGA-based LPU products were to national research institutes such as the Electronics and Telecommunications Research Institute of Korea (ETRI) and the Korea Electronics Technology Research Institute (KETI). FPGAs are provided under the condition of built-in operation due to the limited computing capacity, and in the second half of the year, we plan to jointly develop a service that combines software and hardware with Trustlab, which develops civil service AI services, and sell it to governments and institutions."
4nm LLM Accelerator ‘Adelia’ chip unveiled by Hyper Accel In November 2024 / source=IT dongA
Next-generation semiconductors are products optimized for inference. Joo-Young said, "GPUs process data in parallel, which is advantageous for training operations to develop AI. The complexity of operations is also much more complex than inference. This area we cannot keep up with the GPU. However, inference, which obtains repeated results by adding new inputs to the trained model, requires more memory bandwidth utilization than computation. Therefore, we designed an LLM processing unit that considers memory efficiency."
The LPU boasts a flexible architecture that allows it to be tailored for customer-specific needs, ranging from low-power inference solutions to high-performance configurations for server environments / source=Hyper Accel
He continued, "Bertha, the second-generation LPU, completed design in April of this year and will manufacture at Samsung Foundry using 4nm process thro
ugh the process of logic synthesis and chip placement on the substrate to implement the blueprint as a physical circuit. In the first half of next year, we will conduct a proof of concept (PoC) on Naver Cloud based on engineering samples, and after verification, we will start mass production from the second half of next year."
HyperAccel LPU: Optimized for Inference from the Ground Up
Although Nvidia's GPUs are still the trend in the AI industry, AI semiconductors at home and abroad are also expanding their adoption into the inference field. In particular, each semiconductor company is targeting its own market by presenting an optimized reasoning area. I asked about the design features of the HyperAccel LPU. Joo-Young said, "A GPU is a compute-oriented processing device that integrates numerous CUDA cores. It is a design that takes data, mounts it in chip memory, and calculates quickly through parallel calculations. It puts data into on-chip memory and writes and reads repeatedly," he said, explaining the basic design of GPUs.
He continued, "LPU is a processor that optimizes the amount of data movement per second that determines LLM inference performance. The LPU core with a proprietary technology called Streamlined Dataflow minimizes unnecessary movement of data. When model data is input to multiple LPU cores, each core produces inference results. Typical GPUs only support 50~60% of memory performance even after optimization, but LPUs achieve approximately 90% of maximum memory bandwidth. This is accomplished by applying a technology element called Streamlined Memory Access (SMA). SMA directly connects data fetched from external memory to the actual matrix and vector processors without bandwidth loss or data conversion."
Joo-Young likened the semiconductor AI processing to a factory to aid understanding. Semiconductor memory, which store data, can be thought of as a raw material warehouse. The logic die, composed of chips, is the actual assembly workshop. A GPU is like a massive factory with thousands of workers who can perform any task well. They handle everything from simple tasks like making teddy bears to complex manufacturing like assembling cars. However, all tasks must be performed sequentially, causing bottlenecks on the factory lines moving work from the GPU raw material warehouse to the workshop. In contrast, LPUs feature specialized production lines optimized for specific tasks, significantly reducing bottlenecks from raw materials to the workshop.
I thought HBM is the mainstream choice so why do you introduce LPDDR?
A notable aspect is the use of LPDDR5X, a low-power memory, rather than high-bandwidth memory (HBM). While the current trend in AI semiconductors is to adopt HBM for high-capacity memory, Bertha utilizes memory typically used in mobile devices. Joo-Young stated, “The reasons for incorporating LPDDR5X are threefold: securing high capacity, low-power performance, and stable supply and pricing. The NVIDIA H100 GPU uses 80GB HBM, while our LPU is planned to be equipped with 128GB LPDDR memory. To run a 60B (60 billion parameter) model, 120GB of memory is required. Using the H100 would necessitate two units, whereas the LPU can handle it with just one 128GB model."
Configuration of HBM(left), LPDDR5X memory(right) / source=IT dongA
On the low power and demand side, "LPDDR is literally Low Power DDR memory, which consumes less power than HBM. Power consumption is a major factor in the operation of data centers from construction to operation. In addition, HBM has high demand and insufficient supply so there is potential for product delays and price increases due to demand-supply imbalances. On the other hand, LPDDR is widely used in industries other than semiconductors, making supply readily available and prices stable. In terms of cost, the price per 1GB is one-third to one-fifth the cost of HBM, and it does not require the latest manufacturing processes which also helps reduce future manufacturing costs."
He added, "LPDDR has many advantages, but it is relatively weaker in terms of transmission speed and bandwidth. We intend to overcome this limitation as much as possible with HyperAccel's LPU technology and processing efficiency (Batch) inventory to pursue a strategy to target the market with an economical price.”
Next-generation semiconductors are expected to be 10x more cost-effective and 5x higher performance per watt than GPUs
Whether AI semiconductors can substitute for GPUs is a question that has been presented to the industry as a whole. Orion, an FPGA server released by HyperAccel in 2023, achieved 1.33x higher energy efficiency than NVIDIA's H100 and 1.32x higher energy efficiency than L4, but now it needs to be updated with the emergence of Blackwell, which has higher performance. HyperAccel aims to stimulate the market with an 4nm ASIC scheduled for release next year.
Bertha is a 4nm process-based LPU that will be released next year / source=IT dongA
Joo-Young stated, “The LPU ASIC semiconductor currently under development using Samsung's 4nm process supports various precision levels for quantization, including FP16, FP8, FP4, BF16, INT8, and INT4. While many technologies exist for quantizing model parameters, we are developing a technology that quantizes even the KV cache, which reuses computational information.” He added, “We expect the 4nm ASIC to achieve over 10x higher price-performance compared to GPUs and approximately 5x higher power-performance. This is the result of combining a streamlined dataflow architecture, the adoption of LPDDR5X instead of HBM, and an LPU engine specialized for LLM inference.”
HyperAccel's 4nm ASIC will support LLMs capable of multimodal analysis of complex audiovisual data, agent AI that automates decision-making processes, and Stable Diffusion. Future plans include deploying it as an on-device AI chip capable of operating independently without a network connection. Since the server product has already been designed, we expect rapid releases of on-device LLM prototypes utilizing the developed LPU engine.
Hyper Accel also supports 'HyperDex' software to help LPU run stably / source=Hyper Accel
Not overlooked is software support to increase utilization in the field going beyond just performance and efficiency. Joo-Young explained, “HyperDex is a comprehensive software system that includes a model parallelization layer for distributing models across multiple devices, a model mapper for converting each model to fit the device, an LPU compiler that generates instructions for the LPU to process model computations, and the device runtime and drivers necessary to run multiple LPUs.”
He continued, “The HyperDex SDK is compatible with all the latest software frameworks and can be integrated with any model registered on Hugging Face,” and added, “It also supports compilation using PyTorch, and we plan to provide SDKs from our partners this year to enable more people to use LPU computing.”
A heterogeneous semiconductor market that combines GPUs, NPUs, LPUs, and DPUs is on the horizon
As the next-generation semiconductor is scheduled to be released next year, this year will focus on development and product validation. However, work to secure use cases for AI semiconductors continues. Joo-Young stated, "Earlier this year, HyperAccel secured the overall project for the K-Cloud development initiative led by the Ministry of Science and ICT. This project involves implementing domestic AI as an actual data center service and achieving the world's third-highest ranking in the MLPerf inference energy efficiency category. While some argue that MLPerf focuses on hardware testing, which is detached from real service environments, it remains the most discriminative and credible test available. We will also collaborate with Naver Cloud to establish a test environment that measures AI semiconductor performance in actual service environments."
Finally, Joo-Young said, "We don't need to beat NVIDIA's GPU in every aspect. The future AI systems we envision will require heterogeneous semiconductor combinations that integrate specialized chips like GPUs, NPUs (Neural Processing Units), LPUs, and DPUs (Data Processing Units) to deliver optimal performance at optimal cost. While GPUs alone still dominate the market, the time will come when they must keep pace with other products. We will strive to establish HyperAccel's LPU as an indispensable solution in the heterogeneous computing environment and deliver on dramatically reducing the cost and power of existing computing platforms."
By Si-hyeon Nam (sh@itdonga.com)




![“정원오-오세훈, 5%p내 접전 벌일것…吳 올라서가 아니라 鄭이 빠져서”[정치를 부탁해]](https://dimg.donga.com/c/138/175/90/1/wps/NEWS/IMAGE/2026/05/18/133944130.1.jpg)
