
“ENERZAi Performs Strongly in the Global Edge AI Market with Extreme Low-bit Quantization Technology”
“ENERZAi Performs Strongly in the Global Edge AI Market with Extreme Low-bit Quantization Technology”
Posted May. 08, 2026 11:22,
Updated May. 08, 2026 11:24
- Extreme low-bit quantization (such as 1.58-bit) is emerging as a key technology, enabling large AI models to run efficiently on small devices with reduced memory and power.
- Companies like ENERZAi are leading commercialization efforts, proving that high-performance AI can run locally without cloud dependence.
According to the AI Quantization Tools Market Report 2026 published by market research firm MarketsandMarkets, the model quantization market is projected to grow at a CAGR of 19%, rising from $920 million (approx. 1.36 trillion KRW) last year to $1.09 billion (approx. 1.61 trillion KRW) this year. This growth trend is expected to maintain a rate of 19.2% through 2030, reaching a market size of $2.2 billion (approx. 3.26 trillion KRW). The pace of growth could accelerate further due to the increasing adoption of Edge AI and on-device AI. Furthermore, on-device AI, which computes AI tasks directly on the device to overcome the expansion limits of AI data centers, is emerging as a key solution, ensuring a clear path for growth.

By utilizing AI model quantization, high-performance AI technology can be leveraged even on ultra-small devices.
The market can be broadly segmented based on the environment in which quantization technology is applied: ▲ high-precision quantization for GPUs, standard hardware for data centers, and cloud services; ▲ low-precision quantization for on-device AI; and ▲ ultra-low precision quantization tailored for Edge AI device levels. For server-level hardware quantization, FP8 precision—which reduces 16-bit (FP16)—was the mainstream until 2024, but now FP4 units, such as NVIDIA's NVFP4, are also being utilized. In the field of general-purpose PTQ (Post-Training Quantization) used for AI inference engines, various techniques are widely employed, including GPTQ, which minimizes errors, and AWQ, which focuses on salient values.
For technologies for efficiently running Large Language Models (LLMs) on devices such as personal PCs or workstations, quantization techniques that allocate different bit counts based on importance are being used. Alongside these, formats for executing quantized models, such as GGUF, are widely utilized, and techniques like EXL2—a 3-to-5-bit optimization technology for NVIDIA GPUs—are being applied in certain environments. Utilizing AI model quantization technology allows for the efficient operation of AI with fewer resources, achieving total cost of ownership (TCO) reductions, power efficiency, and on-device AI implementation simultaneously.
From Startups to Big Tech: The Race for Ultra-Low Precision Quantization
Among these, ultra-low precision quantization is the field where the most intense competition is occurring. By using ultra-low precision quantization technology, AI can be operated within the device even on ultra-small hardware. Currently, in the field of ultra-low precision quantization, the 1.58-bit language model 'BitNet', announced by Microsoft, is garnering significant attention. BitNet is notable because it adopts an approach where the model structure itself is designed specifically for an ultra-low precision environment, unlike existing quantization methods. However, this technology has not yet reached general-purpose maturity, and attempts to combine it with various techniques, including N:M structural sparsity, are being actively discussed at the research stage. N:M structural sparsity is a technology that turns low-importance information into zeros according to rules that hardware can easily understand. Its characteristic is that while the amount of data is reduced by nearly half, it becomes a structured format with predictable positions.
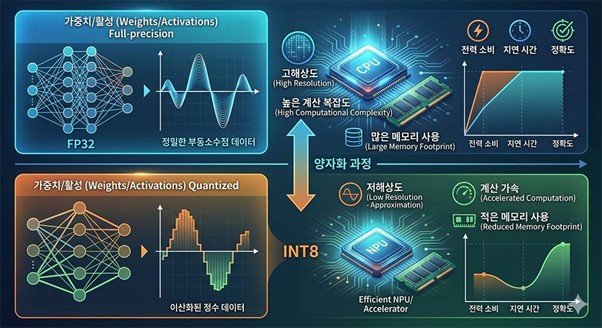
The key is to run AI models at lower precision than the default FP32 to boost efficiency. At this time, minimizing accuracy loss is the core technology of AI quantization companies.
The ultra-low precision quantization field is not yet dominated by a specific company; rather, various approaches are evolving competitively, centered around global Big Tech companies and the open-source community. In the United States, major companies such as Red Hat and NVIDIA have entered the related market by acquiring startups. In China, Tencent is confirming the marketability of ultra-low precision quantization in industrial settings based on the Angel slim framework. Global AI communities, including the open-source AI platform Hugging Face, are also actively sharing implementations and use cases related to low-bit models. In South Korea, ENERZAi is focusing on 1.58-bit quantization and is collaborating with Synaptics, Broadcom, Advantech, MediaTek, and Qualcomm.
ENERZAi: Taking the Global Lead at the Bit-Level
ENERZAi is developing extreme low-bit quantization technologies, including 1.58-bit quantization, alongside its proprietary AI inference engine, Optimium. By leveraging ENERZAi's quantization expertise, AI can be run even on general-purpose Edge AI devices that lack dedicated AI chips, and on AI devices, it can deliver superior AI performance compared to conventional computing environments. In an optimized quantization environment, the core technology maintains nearly 100% accuracy while doubling inference speed, reducing the AI model's memory usage fourfold, and cutting power consumption threefold.
As there are few companies worldwide dealing with ultra-low precision quantization, ENERZAi has been attracting growing industry attention. Looking at the first quarter of this year alone, the company participated in CES (Consumer Electronics Show) in January, followed by the world's largest mobile communications exhibition, Mobile World Congress (MWC26), held in Barcelona, Spain. Immediately after, they attended Embedded World 2026, a specialized exhibition for global embedded systems, EDGE AI San Diego 2026, and NVIDIA GTC 2026, introducing their technology to companies around the world.

Hanhim Chang, CEO of ENERZAi, is introducing the technology to visitors at the MWC 2026 site.
At CES 2026, held between January 6 and 9 this year, the company participated as part of the K-Startup Pavilion. On-site, they showcased a voice-based command control model and a subtitle generation and translation model, both running in real time on-device on Arm-based Edge SoCs using their extreme low-bit quantization technology. As CES is an event where consumer products are mainstream rather than corporate or industrial ones, they aimed to introduce their technology to the general public.
Their full-scale activities began with MWC 2026, held from March 2 to 5. ENERZAi attended the MWC satellite event 4YFN alongside 15 startups supported by SK Telecom. On-site, they demonstrated a live translation model between English and Spanish running on a single small device, with a model size of only a few hundred MBs and no reliance on the cloud.

An example of a Speech RAG model implemented on an Advantech AOM module; the fact that a Speech RAG can run on a power-efficient device suitable for real-world deployment is significant in itself.
Immediately following that, on March 11, they participated in Embedded World alongside major partners such as NXP, a Dutch system semiconductor company, and Synaptics, an American Edge AI and IoT specialist. NXP is a specialist in automotive semiconductors and supplies various industrial and robotic chips. Recently, it has been expanding its business as a platform company for Software-Defined Vehicles (SDV). Synaptics, known as a laptop touchpad driver and fingerprint sensor company, now handles the 'Astra' AI processor lineup for smart home devices, industrial robots, and wearables, as well as the Veros chipset supporting standard wireless connectivity like Wi-Fi 7.
In collaboration with NXP & Advantech, they implemented a Speech RAG (Retrieval-Augmented Generation) model on an Advantech system module equipped with NXP’s next-generation i.MX95 chipset. Speech RAG is a model that recognizes speech and generates responses by retrieving and referencing relevant knowledge. The fact that this was implemented entirely on-device without an internet connection is a notable highlight.

ENERZAi and GRINN exhibited a robotic arm and gripper at the Synaptics booth during Embedded World 2026.
Synaptics is also collaborating in the field of Physical AI. At the event, they demonstrated an on-device voice-based robotic arm and gripper control system made by the Polish IoT company GRINN using the Synaptics Astra chip. Currently, robots perform based on predefined algorithms or require separate control systems, but this was made possible through ENERZAi’s on-device voice command model. Additionally, a presentation was delivered in the ‘New Embedded Vision and Audio Technology’ session on the topic of ultra-low precision quantization technology for the real world.
Realizing LLM Operation on Ultra-Small Devices with Ultra-Low Precision Quantization
The reason ENERZAi's technology is drawing attention is that it is a way to significantly expand the range of Large Language Model utilization on small devices like smartphones. At NVIDIA GTC 2026 held last March, they succeeded in implementing the Meta Llama 3.1-8B model on a Jetson Orin Nano system with 8GB of memory using only 2.5GB of memory.

Meta Llama 3.1-8B on NVIDIA Jetson Orin Nano: ENERZAi's technology reduces GPU memory usage from 5.2GB (4-bit quantization, left) to 2.5GB (1.58-bit, right)
The Llama 3.1-8B requires 16GB of memory under the FP16 standard, and even with INT8 optimization, at least 8GB is necessary. The key was implementing the model with only 2.5GB of memory by utilizing quantization of 2 bits or less. To interpret this more drastically, it means that on-device AI could be run on a gaming laptop equipped with an NVIDIA GPU with less than 4GB of memory. This achievement was presented at GTC under the session titled 'Method for Running 8B LLM on Edge GPU using 1.58-bit Quantization'.
At EDGE AI San Diego 2026, they implemented an AI Agent combined with an LLM container based on WEDA, Advantech's software development environment and system. They also directly implemented custom kernels for 1.58-bit operations used in Microsoft BitNet on the Qualcomm AI Stack (QNN) for the Qualcomm Hexagon NPU, extending beyond its native support. Neural processing units typically rely on software toolchain provided by chip vendors, such as QNN. By overcoming these limitations through their implementation, ENERZAi has enabled broader deployment of extreme low-bit AI models across diverse use cases. Broadly speaking, this also means that AI models can be operated without an internet connection on high-end smartphones with 8GB or more of memory.
ENERZAi's Quantization Technology: Moving Beyond the Testing Phase into Commercialization

ENERZAi maintains a technical cooperation relationship regarding Synaptics' Edge AI semiconductors.
AI quantization technology is a technology that will raise the growth limits of the AI semiconductor ecosystem, and 2026 is the year when full-scale commercialization begins. Synaptics, which has collaborated with ENERZAi through a series of co-marketing and co-selling activities showcasing ENERZAi’s extreme low-bit AI models running on Synaptics’ platforms, has recently expanded its collaboration to include the AI compiler domain. An AI compiler performs the function of translating AI models so that they work on specific hardware.
Synaptics is developing Torq, its core software stack, to strengthen its Edge AI capabilities. Recently, the company has shifted toward a more open strategy by releasing parts of its MLIR/IREE-based compiler and toolchain as open source, aiming to improve compatibility and expand its ecosystem. In this context, Synaptics and ENERZAi have initiated a collaboration to further enhance the capabilities of the Synaptics Torq MLIR-based compiler and runtime. This joint development initiatives leverages ENERZAi’s proven expertise demonstrated through ENERZAi’s proprietary AI compiler, Optimium, and meta-programming language, Nadya, to enhance compatibility and foster growth in the open-source Edge AI developer ecosystem.
Furthermore, they are on the verge of signing a licensing agreement with a large European corporation and are currently in contract negotiations with various Edge AI companies in South Korea across sectors such as defense, automotive, home appliances, telecommunications, and kiosks.
Edge AI Industry: 2026 Will Be the First Year of Scalability and Commercialization
Until now, the Edge AI market was regarded as a supplementary field dependent on server environments due to limited performance. However, as semiconductor performance has strengthened and AI quantization technology has advanced, the implementation of high-level AI models on Edge AI semiconductors has become possible, reversing the situation. The possibility has opened up for distributing the load of saturated AI data centers to Edge AI devices to enhance speed, power efficiency, and stability. In particular, AI model quantization is a core technology that enables high-performance AI to be implemented even on small devices, so the attention of the entire AI industry is expected to remain very high.

On March 28, ENERZAi, with the support of Advantech and Synaptics, held the 'AI on Edge - From bits to real world' seminar for domestic Edge AI developers.
Interest is also high both domestically and internationally. In the 'AI on Edge - From bits to real world' seminar held by ENERZAi at the end of last March, dozens of domestic AI edge technology and semiconductor experts directly participated to share and discuss cases of AI model quantization technology. Moreover, the Edge AI and Vision Alliance, a world-renowned Edge AI association, recognized their technological prowess by selecting ENERZAi's extreme low-bit voice and language model as the Product of the Year. The award-winning work will be showcased at the Embedded Vision Summit to be held in the United States this May.
ENERZAi's journey of success goes beyond the fact that their technology is widely recognized; it shows that AI quantization technology will emerge globally in the future. Global Big Tech companies began securing technical dominance several years ago, and the fact that the technology of startups like ENERZAi is receiving significant attention proves this. As the semiconductor market enters the sub-2nm era, the performance of Edge AI is also developing leaps and bounds, and the market seeks to embed even higher performance AI into it. Starting this year, Edge AI and ultra-low precision quantization technology are expected to enter the phase of commercialization.
By Si-hyeon Nam (sh@itdonga.com)





